Documentum on PostgreSQL
September 17, 2013 at 3:53 pm | Posted in Performance | Leave a commentTags: database, documentum, Greenplum, machine learning, NLP, postgres
Great news from Lee Dallas reporting from the Documentum Developer Conference: Documentum Developer Edition is back and now runs on PostgreSQL. I discussed this a few months back and I thought that maybe EMC didn’t have the stomach for something so technical, but I was wrong. So kudos to EMC.
Lee mentions it’s not yet production ready, so hopefully that is in the pipeline. After that how about certifying it to run on Greenplum, EMC’s massively scalable PostgreSQL. Then the sky is the limit for large-scale NLP and machine learning tasks. For example last year I wanted to run a classification algorithm on document content to identify certain types of document that couldn’t be found by metadata. There are plenty of other uses I can think.
I’ll be downloading the edition as soon as possible to see how it runs.
Documentum and Databases
July 3, 2013 at 4:11 pm | Posted in Performance | 4 CommentsTags: documentum, Greenplum, postgres
Here’s a quick thought on Documentum and databases. For a long time Documentum used to support a variety of databases however these days support is just for 2 in D7 (Oracle and SQL Server) down from 4 in D6.7 (the previous 2 plus DB2 and Sybase).
The clear reason for narrowing down the choice of database server is (I suspect) the cost of developing for and supporting a large number of choices, particularly since most of the database/OS combinations were used by only a handful of customers.
So why doesn’t EMC port the application to postgres and cut that choice down to 1? Why postgres? Well because EMC owns Greenplum (well actually it’s now part of Pivotal but that just complicates the story) and Greenplum is an enhanced postgres.
The logic for this is clear: EMC would like people to move to OnDemand and it makes sense for them to have ownership of the whole technical stack. At the very least they must be shelling out money to one of the database vendors. I’m not sure which one – if you have access to an OnDemand installation try running ‘select r_server_version from dm_server_config’ and see what’s returned, someone let me know the results if you could.
There are a couple of reasons why EMC might be reluctant. First it’s a big change and people (including EMCs own development and support teams) have a big skills base in the legacy databases. Taking a medium-term strategic view this is not a great reason and is just a product of FUD – Documentum has taken brave technical steps in the past such as eliminating the dmcl layer with great success.
Second we’ve been hearing a lot over the last few years about the NG server that runs on XHive xml database that is touted to replace the venerable Content Server in the longer term. Perhaps EMC is reluctant to work on 2 such radical changes.
Who knows? It’s just a thought …
Customising Documentum’s Netegrity Siteminder SSO plugin pt 1
May 24, 2013 at 9:05 am | Posted in Architecture, Development | Leave a commentTags: authentication plugin, content server, documentum, Netegrity, single sign on, SiteMinder, SSO
This article introduces the motivation and architecture behind web-based Single Signon systems and Documentum’s SSO plugin. The 2nd part of the article will discuss limitations in the out of the box plugin and a customisation approach to deal with the issue.
Overview
For many users having to enter a password to access a system is a pain. With most enterprise users having access to multiple systems it’s not only an extra set of key presses and mouse clicks that the user can do without but often there are lots of different passwords to remember (which in itself can lead to unfortunate security issues – e.g. writing passwords on pieces of paper to help the user remember!).
Of course many companies have become keen on systems that provide single sign on (SSO). There are a number of products deployed to support such schemes and Documentum provides support for some of them. One such product is CA Site Minder – formerly Netegrity SiteMinder and much of the EMC literature still refers to it as such.
SiteMinder actually consists of a number of components; the most relevant to our discussion are the user account database and the web authentication front-end. SiteMinder maintains a database of user accounts and authentication features and exposes an authentication API. Web-based SSO is achieved by a web-service that provides a username/password form, processes the form parameters and (on successful authentication) returns a SSO cookie to the calling application.
Documentum’s SiteMinder integration consists of 2 components. A WDK component that checks whether a SSO cookie has been set and a Content Server authentication plugin that will use the SiteMinder API to check the authentication of a user name/SSO cookie authentication pair.
How it works
As usual it’s best to get an understanding by looking at the flow of requests and messages. Let’s take the case of a user opening a new browser session and navigating to a SSO-enabled WDK application (it could be webtop, web publisher or DCM). In Figure 1 we see a new HTTP request coming into the application server. At this point there is no SSO cookie and code in the WDK component can check this and redirect to a known (i.e. configured in the WDK application) SiteMinder service. I’ve also seen setups where the app server container itself (e.g. weblogic) has been configured to check for the SSO cookie and automatically redirect.
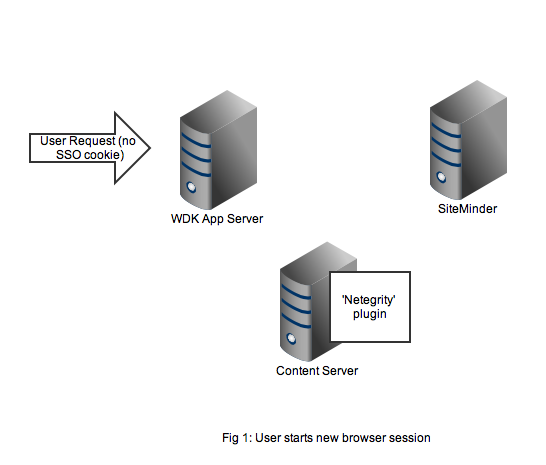
Redirection to the SiteMinder service will display an authentication form, typically a username and password but I guess SiteMinder also has extensions to accept other authentication credentials. As shown in Figure 2, on successful authentication the response is returned to the client browser along with the SSO cookie. Typically at this point the browser will redirect to back to the original WDK url. The key point is any subsequent requests to the WDK application will contain the SSO cookie.
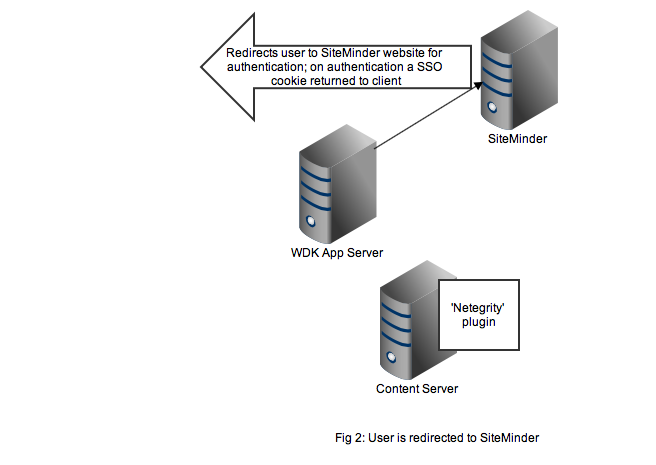
Any user that wants to perform useful work in a WDK application will need an authenticated Documentum session. In non-SSO Documentum applications our user would have to authenticate to the Content Server via a WDK username/password form. In SSO Documentum applications, if we need to authenticate to a Content Server (and we have a SSO cookie) WDK silently passes the username and SSO cookie to the Content Server. Our SSO-enabled Content Server will do the following:
- Look up the username in it’s own list of dm_user accounts
- Look to see that the user_source attribute is indeed set to ‘dm_netegrity’
- Passes the username and SSO token (i.e. the cookie) to the dm_netegrity plugin to check authentication
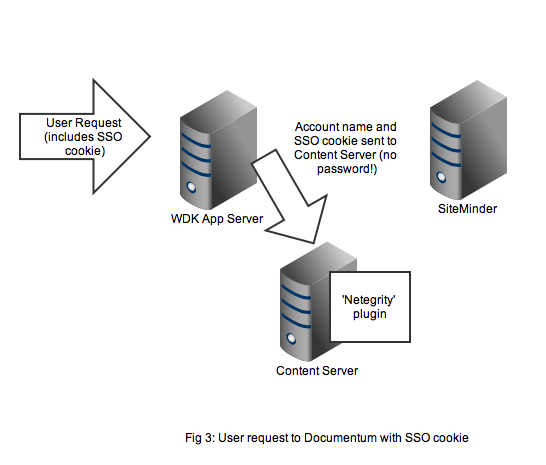
Figure 4 shows that the netegrity plugin will contact the SiteMinder service using the authentication API. The SiteMinder server confirms 2 things. First that the user account is indeed present in its database and secondly that the SSO token is valid and was issued for that user.
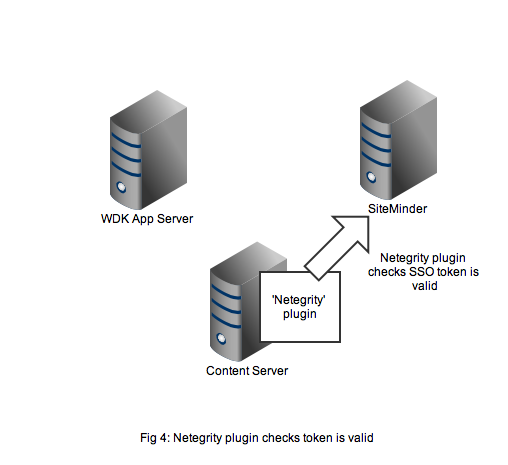
In Figure 5 we see that a successful authentication of the SSO token with SiteMinder means that the Netegrity plugin confirms authentication to the content server. A valid Documentum session will be created for the user and the user can continue to work. All without any Documentum user account and password form being displayed.
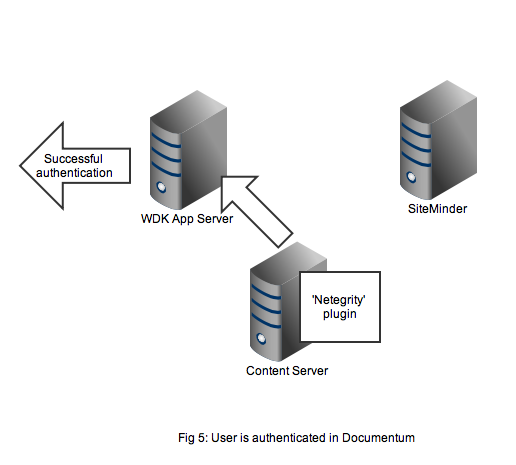
That concludes the overview of the out of the box working of the Documentum SiteMinder integration. The 2nd part of this article discusses a problem that manifests in compliance situations.
Documentum and Greenplum
January 14, 2013 at 8:30 am | Posted in Big Data | 1 CommentTags: Big Data, documentum, Greenplum, xCP
@Mikemasseydavis tweeted “will we see #documentum and #greenplum become a ‘platform'”. This aphorism obviously had some attraction since myself and 2 others retweeted it. In a way this is not a completely new idea as Generalli Hellas backed the notion of ‘xCP as the action engine for Big Data‘ which was one of the big ideas that came out of Momentum 2011. In fact EMC seem to have big ideas in this area as evidenced here.
I would ask the following questions:
- How much effort are EMC going to put into this area? How fast will they be able to deliver?
- Does a Greenplum connector for xCP and a feed into Greenplum constitute a platform? What else is needed to make it a platform?
- What are the use cases? Gautam Desai mentions a document with 20 use cases.
Supporting Testing
November 30, 2012 at 10:30 am | Posted in Performance | Leave a commentTags: documentum, JMeter, load testing, LoadRunner, testing
When the designers of WDK sat down to design the framework one thing I don’t think they did was decide to make it easy to test. Anyone who has tried to design scripts for load runner, JMeter or any other tool will have experienced the pain of trying to trap the right dmfRequestId, dmfSerialNum and so on. As for content transfer testing it is really only possible with the unsupported Invoker tool that comes with the load runner scripts.
So my question is to IIG-do xCP and D2 and any other new interface coming out of IIG make it easier to test?
Thoughts on EMC On Demand
November 29, 2012 at 7:22 am | Posted in Architecture | 2 CommentsTags: BOCS, branch office caching services, cloud, d2, documentum, emc, ondemand, xCP
I think EMC first started talking about On Demand at EMC World 2011. The idea is seductive and logical: rather than have to procure your own hardware, install and configure the software, and manage and administer the running system you get EMC to do it for you. The potential benefits are enormous.
First, economies of scale for running hardware in the same way as similar cloud-based offerings. By running on virtual machines and providing scale out options you potentially only have to pay for what you use.
Secondly, experts who can specialise in various aspects of installation, administration and troubleshooting. Furthermore there is an obvious incentive for EMC to focus on initiatives to simplify and automate tasks. Presumably that was the idea behind xMS, the deployment technology recently released with D7.
As a consequence of that last point it gives EMC a great way to collect usage data, bug information and performance insights.
Finally I see great potential in distributed content, allowing content to be replicated across data centres closer to the user. On-premise installations currently rely on solutions like BOCS or content replication to deliver better performance to users in remote offices. These can be tricky to configure without expert help and rely to a greater or lesser extent in having servers in locations where the organisation doesn’t want them.
So clearly I see big benefits, at least in theory. I have several thoughts around OnDemand some of which I hope to explore in future posts; in this post I want to talk about some potential drawbacks and how EMC might address them.
The first question people seem to ask is how will I be able to install and manage our customisations if EMC are managing everything? In fact I expect EMC to put significant limits on how much customisation you will be allowed in OnDemand environments. Which means that the arrival of xCP 2.0 with its ‘configure don’t code’ mentality (and D2s ui configurability) is serendipitous indeed. In fact I doubt OnDemand would really be workable for WDK-based apps like Webtop, DCM and Web Publisher; no-one runs these apps without considerable coded customisations.
Secondly, for some organisations moving content to the cloud will remain problematic as they will have regulatory requirements, or internal security needs, that mean certain types of content can’t reside in particular jurisdictions. This is by no means insurmountable and EMC will need plenty of distributed locations to satisfy some clients. However it does make the Amazon AWS model of ‘click and go’ server resourcing much more difficult for EMC.
Finally from a personnel perspective how will EMC deliver the necessary staffing of data centres if OnDemand really takes off? Running data centre operations is not a core business for EMC ( as far as I know). My assumption is that they won’t be building or running the hardware operations themselves but are partnering with existing companies that have the know how. However even setting up and staffing the software side is new to EMC. Does it have the existing capacity already or will it need to recruit? Or will much of OnDemand be farmed out to partners? Will they run 24×7 from the US or (more likely) use a follow the sun philosophy.
Time will obviously tell but I remain optimistic that OnDemand will be a success – it will depend heavily on the execution in what is a new area for EMC.
How Documentum Print Control Services Works
December 15, 2011 at 1:18 pm | Posted in Architecture | 1 CommentTags: documentum, PCS, print control services
This is the second part of a mini series of articles on Documentum Print Control Services (PCS) and how to use it effectively. The first part provided an introduction and overview of PCS. In this article I will take a much more in-depth technical look at the product.
PCS consists of a number of components:
- A DFS-based web service that is deployed on a JBoss application server
- A set of DARS that contain services that can be used by user-facing applications
- Optional WDK components for Webtop and Taskspace (as mentioned in the first article this PCS support is built into Documentum Compliance Manager)
As we will see later PCS also relies on PDF and Postscript rendition generation so DTS or ADTS is required.
So what happens when a controlled print request is issued from an application? The printing user-interface will usually collect some information from the user relating to the object to be printed. This will include the name of the printer and a reason for the print. Once the request is received by the application server control will be passed to the PCS ControlPrintService.requestPrint() function.
The requestPrint function does 3 things. First PDF Stamping Services (PSS) is used to create a watermarked copy of the main PDF rendition. I may cover PSS in more depth in another article, however the key point here is PSS takes an existing PDF rendition and generates a watermarked PDF that can include metadata overlaid in headers, footers or other areas of the document. PCS and PSS have tight integration where PSS exposes a Controlled Print-specific configuration and PCS can pass in Controlled Print attributes such as copy number, recipient and printing reason to be watermarked on the document.

Click to view in a new window
Next a dmc_pss_print_copy object is created in the repository. The watermarked PDF is the primary rendition for this object and the object is linked to the /Temp/PCSCopies folder. At this point the object’s print_status attribute is set to ‘Created’.

Finally, a request for a Postscript rendition for the dmc_pss_print_copy object is made. The rendition will have a page_modifier of ‘PS4Print’. The server will wait for up to 2 minutes for the rendition to be generated and then return to the caller. Either way the print_status field is set to ‘PsRequested’. Up to now all the processing is synchronous, but now control is returned to the user of application.

At this point the user is probably expecting the printer to output the printed document, however no print request has yet been sent to a printer, there is simply a dmc_pcs_print_copy object created possibly waiting for Postscript rendition to be created. There are 2 asynchronous task still required to be completed. First the Postscript rendition needs to be created:

Click to view in a new window
Of course it may have been created during the earlier synchronous processing but there is no guarantee. Continuous uninterrupted operation of controlled printing requires that your DTS or ADTS infrastructure is resilient, scalable and sized for all the rendition requests generated in a production environment. If your users have requested prints that don’t seem to be appearing your first port of call for troubleshooting is to confirm that DTS/ADTS is working and that Postscript renditions are being created for your dmc_pss_print_copy objects.
The Print Control Services server is ultimately responsible for sending your document to the required printer. Calling the Print Control Services server is the responsibility of the PcsAsyncPrintJob. For controlled print (and recall) requests to be completed in a reasonable amount of time this job needs to be set to run every couple of minutes and needs to be monitored for regular execution and successful job completion.
When PcsAsyncPrintJob runs it queries for all dmc_pss_print_copy objects that have print_status = ‘PsRequested’.

Click to view in a new window
For each dmc_pss_print_copy object the PCSAsyncPrintJob does the following:
- Ensures that a Postscript rendition has been created. If not no further processing is done on this execution of the job.
- Then calls the remote ControlPrintService DFS endpoint on the PCS server, calling the ‘print’ method.
Once the print request is received by ControlPrintService component the following happens:
- The audittrail is checked to ensure that the same document has not been printed with the requested copy number. If for some reason there is already an audittrail entry for this copy number an error is raised.
- The postscript file is sent to the printer using the Java Printing Service API.
- The service monitors the print job until completion (or failure) and then returns a response to the PcsAsyncPrintJob job.
- Creates an audittrail entry to record the controlled print

The actual “printing” part of PCS is carried out using the Java Printing Services (JPS) API. If you are going to be making use of PCS in your organisation it may be worth your while getting to know the JPS a little better. I’ll discuss JPS in more depth in a later article. Once PCS has sent the document for printing it sets the print_status attribute to ‘PrintRequested’ – this is the last status update for the document. Note you only know that PCS has requested a print from the printer – there is no way for PCS to ‘know’ whether that print was successful and so it can not update the object further.
The key points to take away from this article are as follows:
- First, when the WDK application server returns control back to the user after a print request has been made there is no guarantee that the document has been sent to the printer. There are 2 layers of asynchronous processing required to print a document; depending on the speed, capacity and availability of the relevant servers it may take some time for the print to appear.
- Second the print may even not appear at all if there is a problem with one of the asynchronous components. This fact may not be obvious to the end user who may just assume that printing is “slow”.
An Introduction to Documentum Print Control Services
December 5, 2011 at 1:31 pm | Posted in Architecture | 3 CommentsTags: documentum, PCS, print control services
This is the first part of a mini series of articles on Documentum Print Control Services (PCS) and how to use it effectively.
Documentum PCS originated in the compliance products however from the 6.6 release it is a standalone product. If you haven’t worked in regulated environments before you may be a little unclear as to what its purpose is. PCS “controls” the printing of certain important documents, ensuring that a number of things happen when a “Controlled Print” takes place.
I’ll discuss the what first and then explain the why. First whenever a controlled print of a document is made that fact is recorded in the audit trail. A copy number is associated with the document and recorded in the audit trail entry; if you print another copy of the document then the copy number is incremented. In effect every print of a document is uniquely identified by object id and copy number. In fact PCS works in close tandem with Documentum PDF Stamping Services (PSS) to allow a watermark including the copy number to be overlayed on the printed document.
Additionally every printer in the organisation has to be added to the PCS configuration so controlled prints can only be made to well-known printers. Again the printer to which the print is sent is recorded in the audit trail.
Finally, subsequent to executing the controlled print, it may be necessary to record a ‘Recall’ of the print. A ‘Recall’ is recorded in the audit trail against a unique document print (the object id and copy number). The reasons for needing a recall maybe part of the operational lifecycle – one or more documents may have been superseded by an updated version and so all prints of the old version must be physically removed and that removal needs to be recorded. Alternatively it may simply be that a print was stuck in a printer or damaged or lost. It’s worth bearing in mind that when ‘Recalling’ a document with Documentum PCS the only thing that happens is that the recall is recorded in the audit trail as evidence and for reporting. PCS won’t, for example, halt print requests already sent to the printer.
A recall results in a notification sent to the inbox of interested parties. The recipient has to confirm acknowledgement of the notification, at which point a further audit trail entry is created. Thus there are 3 types of audit entry that can be created:
- On print
- On recall
- Recall confirmed
As pointed out in the comments both print and recall actions require the user to authenticate themselves before they are able to proceed.
So now we know what PCS does but it may not be clear why an organisation would need this functionality. As I alluded to earlier printing control is often used in regulated environments. Typical examples would be pharmaceutical or medical manufacturing, or aircraft production. These activities often take place in a factory or lab and need to follow defined and documented processes. Often this process documentation is physically printed, as online reference to the documentation is inconvenient or difficult.
In these types of scenario it is clearly essential that correct and up-to-date documentation is used by production staff (how happy would you be if certain components on the plane you are flying on were manufactured using out-of-date processes?). Not only does it make sense for management in these organisations to know there is a process to record what documentation is in use and when it is updated but in many cases regulatory authorities will required evidence that such systems are in place and demonstrated to work.
Given the above it is unsurprising that this functionality originated in the Documentum Compliance Manager (DCM) product. In earlier versions of DCM watermarking and print control were achieved using integrations with Liquent’s PDF Aqua products. However PCS was introduced as part of DCM 6.5 sp1 and became a separate product in 6.6. Controlled Print and Recall functions are provided as part of the DCM user interface but the latest release of PCS product comes with components that can be installed in the Webtop and Taskspace interfaces. This is part of EMCs policy of moving compliance functionality into the core stack and making it available to all clients rather than retaining a dependency on specialised interfaces. No doubt these features will be available in the C6 products at a later date.
The next installment will dig into the guts of the PCS architecture to see how it works.
Update (14 Dec 2012): I wonder where the new Life Sciences products announced with D7 will fit in with PCS? Will they use PCS and PSS or is there some other technology to do this?
Momentum 2011 part 1
October 31, 2011 at 12:25 pm | Posted in Performance | Leave a commentTags: documentum, Momentum 2011
It’s been quite a while since I last posted. Life on both a personal and business level has been super hectic for the last 6 months which meant that something had to give. This blog was one of those things and the DFCProf project the other. Things have more or less returned to normal and I hoped to be ready to start blogging by the time Momentum rolled around. And I made it … just!
I intend to get back to some regular posting as well as spend some more time digging into interesting Documentum internals and performance. I’ve already got some interesting topics in the works such as: hardware mistakes, why you should upgrade Documentum Compliance Manager (DCM) if your DCM 5.x installation performs like a dog and what children’s birthday parties can teach us about performance. I’ve also long wanted to write about Documentum folder performance myths.
First things first.My last post, sometime back in May, was from EMC World and my first interest this week at Momentum is how some of the exciting announcements from Las Vegas have panned out over the last 6 months. The really exciting stuff was around Documentum OnDemand, cloud based Documentum, Captiva and DocSciences. How close are we to a real product? EMC has been prone to make big announcements over the last few years and then be slow to follow through with actual production quality product. Will this time be different?
As usual Jeroem van Rotterdam’s future architecture, Next Generation Information Server talk will be eagerly awaited. In addition I’ll be interested to hear how people, especially other customers, have responded to the recent highly marketed Oracle attack on Documentum. Finally since I’ve been working a lot with DCM in recent months I’m interested to hear what the roadmap is for a compliance product. A while back EMC seemed to be pulling back from explicitly supporting an in house Compliance product however the more recent messages don’t seem to back that up. DCM 6.7 is out with substantially improved performance and eSigs, overlays and controlled printing are supported by new product releases.
Create a free website or blog at WordPress.com.
Entries and comments feeds.

You must be logged in to post a comment.