Customising Documentum’s Netegrity Siteminder SSO plugin pt 1
May 24, 2013 at 9:05 am | Posted in Architecture, Development | Leave a commentTags: authentication plugin, content server, documentum, Netegrity, single sign on, SiteMinder, SSO
This article introduces the motivation and architecture behind web-based Single Signon systems and Documentum’s SSO plugin. The 2nd part of the article will discuss limitations in the out of the box plugin and a customisation approach to deal with the issue.
Overview
For many users having to enter a password to access a system is a pain. With most enterprise users having access to multiple systems it’s not only an extra set of key presses and mouse clicks that the user can do without but often there are lots of different passwords to remember (which in itself can lead to unfortunate security issues – e.g. writing passwords on pieces of paper to help the user remember!).
Of course many companies have become keen on systems that provide single sign on (SSO). There are a number of products deployed to support such schemes and Documentum provides support for some of them. One such product is CA Site Minder – formerly Netegrity SiteMinder and much of the EMC literature still refers to it as such.
SiteMinder actually consists of a number of components; the most relevant to our discussion are the user account database and the web authentication front-end. SiteMinder maintains a database of user accounts and authentication features and exposes an authentication API. Web-based SSO is achieved by a web-service that provides a username/password form, processes the form parameters and (on successful authentication) returns a SSO cookie to the calling application.
Documentum’s SiteMinder integration consists of 2 components. A WDK component that checks whether a SSO cookie has been set and a Content Server authentication plugin that will use the SiteMinder API to check the authentication of a user name/SSO cookie authentication pair.
How it works
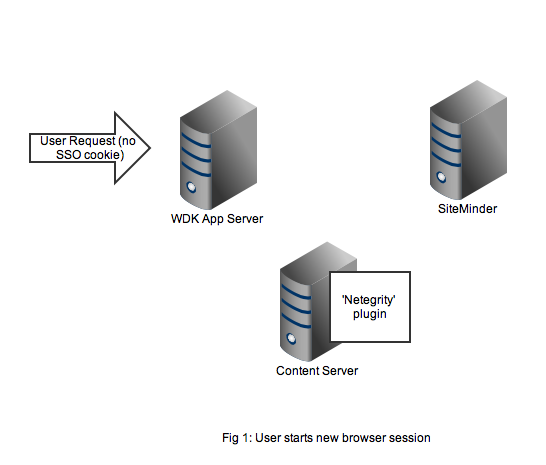
As usual it’s best to get an understanding by looking at the flow of requests and messages. Let’s take the case of a user opening a new browser session and navigating to a SSO-enabled WDK application (it could be webtop, web publisher or DCM). In Figure 1 we see a new HTTP request coming into the application server. At this point there is no SSO cookie and code in the WDK component can check this and redirect to a known (i.e. configured in the WDK application) SiteMinder service. I’ve also seen setups where the app server container itself (e.g. weblogic) has been configured to check for the SSO cookie and automatically redirect.
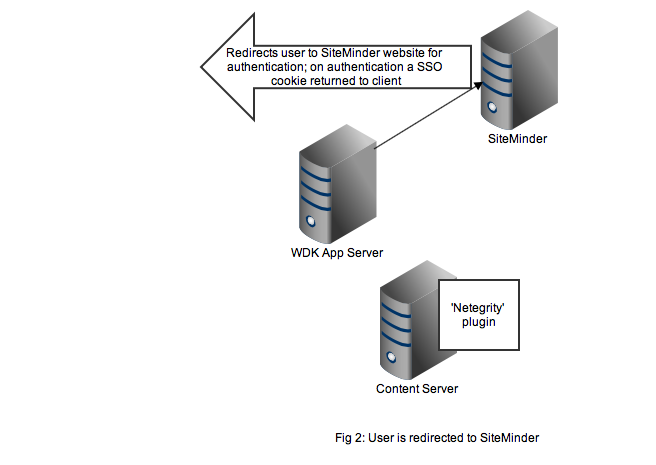
Redirection to the SiteMinder service will display an authentication form, typically a username and password but I guess SiteMinder also has extensions to accept other authentication credentials. As shown in Figure 2, on successful authentication the response is returned to the client browser along with the SSO cookie. Typically at this point the browser will redirect to back to the original WDK url. The key point is any subsequent requests to the WDK application will contain the SSO cookie.
Any user that wants to perform useful work in a WDK application will need an authenticated Documentum session. In non-SSO Documentum applications our user would have to authenticate to the Content Server via a WDK username/password form. In SSO Documentum applications, if we need to authenticate to a Content Server (and we have a SSO cookie) WDK silently passes the username and SSO cookie to the Content Server. Our SSO-enabled Content Server will do the following:
- Look up the username in it’s own list of dm_user accounts
- Look to see that the user_source attribute is indeed set to ‘dm_netegrity’
- Passes the username and SSO token (i.e. the cookie) to the dm_netegrity plugin to check authentication
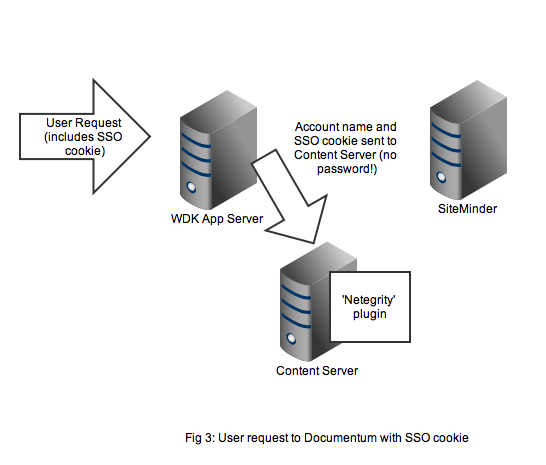
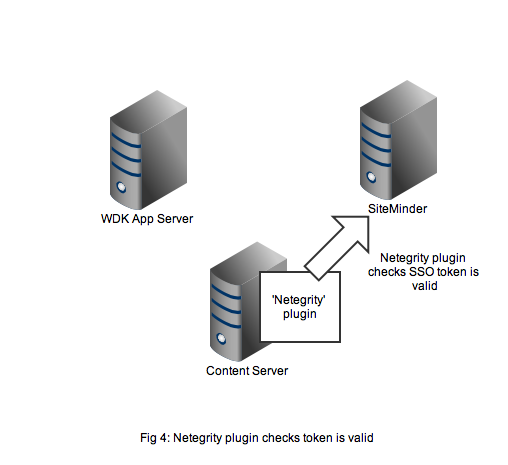
Figure 4 shows that the netegrity plugin will contact the SiteMinder service using the authentication API. The SiteMinder server confirms 2 things. First that the user account is indeed present in its database and secondly that the SSO token is valid and was issued for that user.
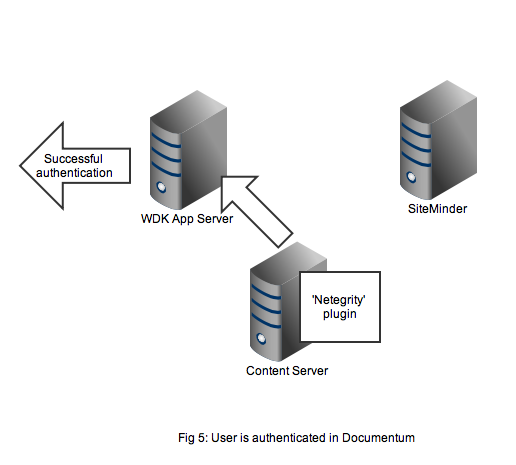
In Figure 5 we see that a successful authentication of the SSO token with SiteMinder means that the Netegrity plugin confirms authentication to the content server. A valid Documentum session will be created for the user and the user can continue to work. All without any Documentum user account and password form being displayed.
That concludes the overview of the out of the box working of the Documentum SiteMinder integration. The 2nd part of this article discusses a problem that manifests in compliance situations.
Taking the EMC Data Science associate certification
May 13, 2013 at 10:06 am | Posted in Big Data, Performance | 12 CommentsTags: Big Data, data science, emc, Greenplum, machine learning, Pivotal
In the last couple of weeks I’ve been studying for the EMC data science certification. There are a number of ways of studying for this certificate but I chose the virtual learning option,which comes as a DVD that installs on a Windows PC (yes Macs are no good!).
The course consists of six modules and is derived from the classroom-based delivery of the course. Each module is dedicated to a particular aspect of data science and big data with each following a similar pattern: a number of video lectures and followed by a set of lab exercises. There are also occasional short interviews with professional data scientists focusing on various topical areas. At the end of each module there is a question and answer multiple-choice to test your understanding of the subjects.
The video lectures are a recording of the course delivered to some EMC employees. This has some pros and cons. Occasionally we veer off from the lecture to a group discussion. Sometimes this is enlightening and provides a counterpoint to the formal material, however sometimes microphones are switched off or the conversation becomes confused and off-topic (just like real life!). Overall this worked pretty well and make if easier to watch.
The labs are more problematic. You get the same labs as delivered in the classroom course however you simply get to watch a camtasia studio recording of the lab with a voiceover by one of the presenters. Clearly the main benefits of labs is to enable people to experience the software hands-on, an essential part of learning practical skills. Most of the labs use either the open source R software or EMCs own Greenplum which is available as a community software download. There is nothing to stop you from downloading your own copies of these pieces of software and in fact that is what I did with R. However many of the labs assume there are certain sets of data available on the system; in some cases this is CSV files which are actually provided with the course. However relational tables used in Greenplum are not provided. It would have been nice if a dump of the relational tables had been provided on the DVD. A more ambitious idea would have been to provide some sort of online virtual machine in which subscribers to the course could run the labs.
Since the lab guide was provided I was able in many cases to follow the labs exactly, where the data was provided, or something close to it by generating my own data. I also used an existing Postgres database as a substitute for some of the Greenplum work. However I didn’t have time to get MADLib extensions working in Postgres (these come as part of out-of-the-box Greenplum). This is unfortunate as clearly one of the things that EMC/Pivotal/Greenplum would like is for more people to use MADLib. By the way, if you didn’t know, MADLib is a way of running advanced analytics in-database with the possibility of using Massively Parallel Processing to speed delivery of results.
The first couple of modules are of a high-level nature aimed more at Project Manager or Business Analyst type people. The presenter, David Dietrich, is clearly very comfortable with this material and appears to have had considerable experience at the business end of analytics projects. The material centres around a 6-step, iterative analytics methodology which seemed very sensible to me and would be a good framework for many analytics projects. It emphasises that much of the work will go into the early Discovery phases (i.e. the ‘What the hell are we actually doing?” phase) and particularly the Data Preparation (the unsexy bit of data projects). All in all this seemed both sensible and easy material.
Things start getting technical in Module 3 which provides background technicals on statistical theory and R, the open-source statistics software. The course assumes a certain level of statistical background and programming ability and if you don’t have that this is where you might start to struggle. As an experienced programmer I found R no problem at all and thoroughly enjoyed both the programming and the statistics.
The real meat of the course is Modules 4 and 5. Module 4 is a big beast as it dives into a number of machine learning algorithms: Kmeans clustering, Apriori decision rules, linear and logistic regression, Naive Bayes and Decision Trees. Throw in some introductory Text Analysis and you have a massive subject base to cover. This particular part of the course is exceptionally well-written and pretty well presented. I’m not saying it’s perfect but it is hard to over-state how difficult it is to cover all this material effectively in a relatively short-space of time. Each of these algorithms is presented with use-cases, some theoretical background and insight, pros and cons, and a lab.
It should be acknowledged that analytics and big data projects require a considerable range of skills and this course provides a broad-brush overview of some of the more common techniques. Clearly you wouldn’t expect participation on this course to make you an expert Data Scientist any more than you would employ someone to program in Java or C just based on courses and exams taken. I certainly wouldn’t let someone loose to administer a production Documentum system without being very sure they had the tough experience to back up the certificates. Somewhere in the introduction to this course they make clear that the aim is to enable the you to become an effective participant in a big data analytics project; not necessarily as a data scientist but as someone who needs to understand both the process and the technicals. As far as this is the aim I think it is well met in Module 4.
Module 5 is an introduction to big data processing, in particular Hadoop and MADLib. I just want to make 1 point here. This is very much an overview and it is clear that the stance taken by the course is that a Data Scientist would be very concerned with technical details about which analytics methods to use and evaluate (the subject of module 4), however the processing side is just something that they need to be aware of. I suspect in real-life that this dichotomy is nowhere near as clear-cut.
Finally Module 6 is back to the high-level stuff of modules 1 and 2. Some useful stuff about how to write reports for project sponsors and other non-Data Scientists and dos and don’ts of diagrams and visualisations. If this all seems a bit obvious it’s amazing how often this is done badly. As the presenter points out it’s no good spending tons of time and effort producing great analytics if you aren’t able to effectively convince your stakeholders of your results and recommendations. This is so true. The big takeaways: don’t use 3D charts, and pie charts are usually a waste of ink (or screen real estate).
If I have one major complaint about the content it is that Feature Selection is not covered in any depth. It’s certainly there in places in module 4 but given that coming up with the right features to model on can have a huge impact on the predictive power of your model there is a case for specific focus.
So overall I think this was a worthwhile course as long as you don’t have unrealistic expectations of what you will achieve. Furthermore if you want to get full value from the labs you are going to have to invest some effort in installing software (R and Greenplum/Postgres) and ‘munging’ data sets to use.
Oh, by the way, I passed the exam!
Create a free website or blog at WordPress.com.
Entries and comments feeds.

You must be logged in to post a comment.