Customising Documentum’s Netegrity Siteminder SSO plugin pt 1
May 24, 2013 at 9:05 am | Posted in Architecture, Development | Leave a commentTags: authentication plugin, content server, documentum, Netegrity, single sign on, SiteMinder, SSO
This article introduces the motivation and architecture behind web-based Single Signon systems and Documentum’s SSO plugin. The 2nd part of the article will discuss limitations in the out of the box plugin and a customisation approach to deal with the issue.
Overview
For many users having to enter a password to access a system is a pain. With most enterprise users having access to multiple systems it’s not only an extra set of key presses and mouse clicks that the user can do without but often there are lots of different passwords to remember (which in itself can lead to unfortunate security issues – e.g. writing passwords on pieces of paper to help the user remember!).
Of course many companies have become keen on systems that provide single sign on (SSO). There are a number of products deployed to support such schemes and Documentum provides support for some of them. One such product is CA Site Minder – formerly Netegrity SiteMinder and much of the EMC literature still refers to it as such.
SiteMinder actually consists of a number of components; the most relevant to our discussion are the user account database and the web authentication front-end. SiteMinder maintains a database of user accounts and authentication features and exposes an authentication API. Web-based SSO is achieved by a web-service that provides a username/password form, processes the form parameters and (on successful authentication) returns a SSO cookie to the calling application.
Documentum’s SiteMinder integration consists of 2 components. A WDK component that checks whether a SSO cookie has been set and a Content Server authentication plugin that will use the SiteMinder API to check the authentication of a user name/SSO cookie authentication pair.
How it works
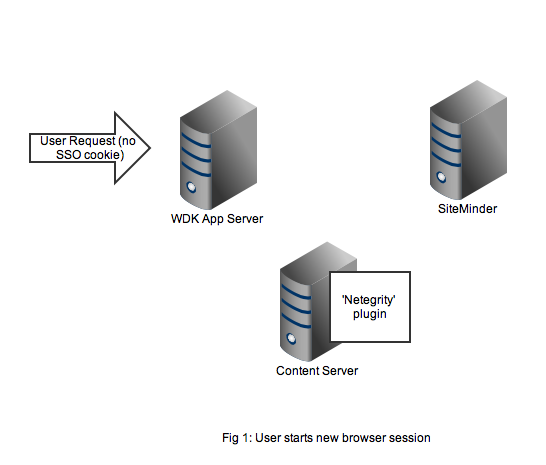
As usual it’s best to get an understanding by looking at the flow of requests and messages. Let’s take the case of a user opening a new browser session and navigating to a SSO-enabled WDK application (it could be webtop, web publisher or DCM). In Figure 1 we see a new HTTP request coming into the application server. At this point there is no SSO cookie and code in the WDK component can check this and redirect to a known (i.e. configured in the WDK application) SiteMinder service. I’ve also seen setups where the app server container itself (e.g. weblogic) has been configured to check for the SSO cookie and automatically redirect.
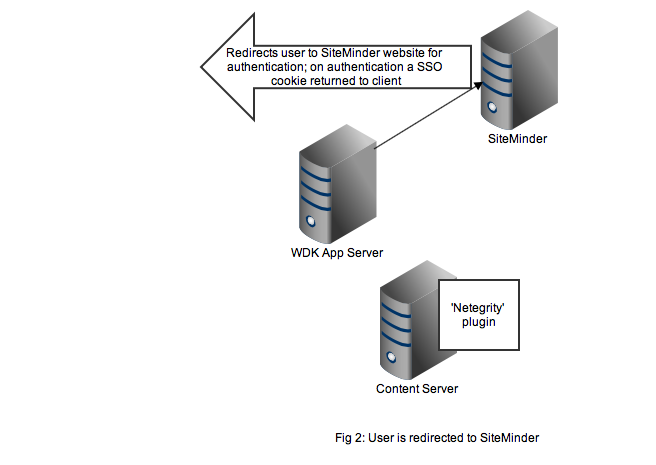
Redirection to the SiteMinder service will display an authentication form, typically a username and password but I guess SiteMinder also has extensions to accept other authentication credentials. As shown in Figure 2, on successful authentication the response is returned to the client browser along with the SSO cookie. Typically at this point the browser will redirect to back to the original WDK url. The key point is any subsequent requests to the WDK application will contain the SSO cookie.
Any user that wants to perform useful work in a WDK application will need an authenticated Documentum session. In non-SSO Documentum applications our user would have to authenticate to the Content Server via a WDK username/password form. In SSO Documentum applications, if we need to authenticate to a Content Server (and we have a SSO cookie) WDK silently passes the username and SSO cookie to the Content Server. Our SSO-enabled Content Server will do the following:
- Look up the username in it’s own list of dm_user accounts
- Look to see that the user_source attribute is indeed set to ‘dm_netegrity’
- Passes the username and SSO token (i.e. the cookie) to the dm_netegrity plugin to check authentication
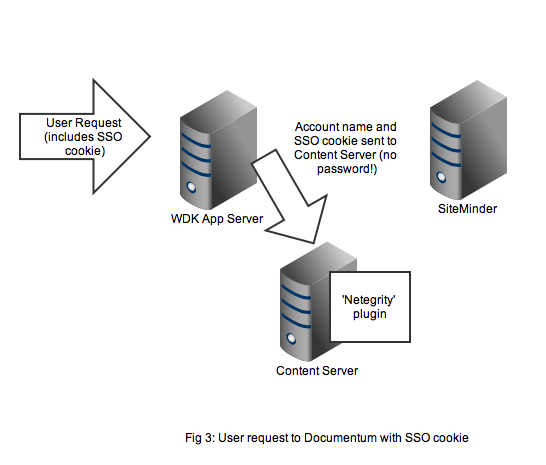
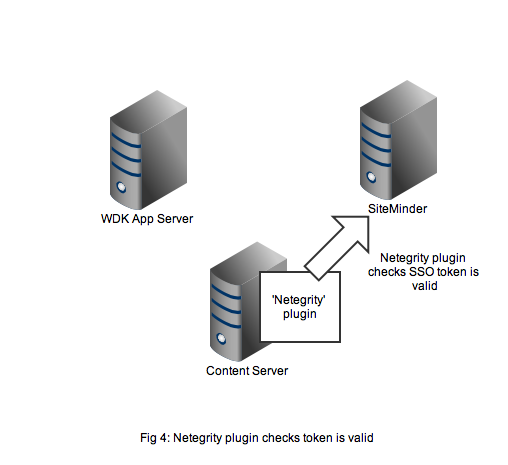
Figure 4 shows that the netegrity plugin will contact the SiteMinder service using the authentication API. The SiteMinder server confirms 2 things. First that the user account is indeed present in its database and secondly that the SSO token is valid and was issued for that user.
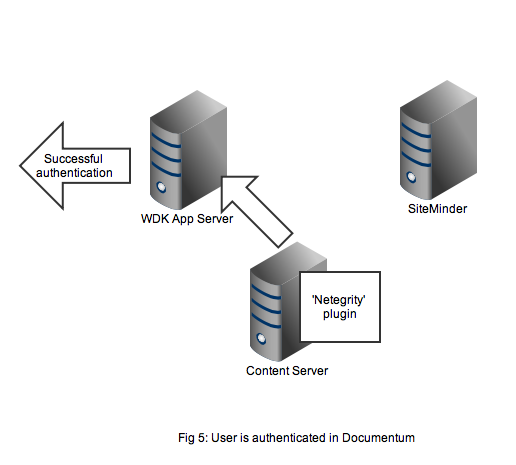
In Figure 5 we see that a successful authentication of the SSO token with SiteMinder means that the Netegrity plugin confirms authentication to the content server. A valid Documentum session will be created for the user and the user can continue to work. All without any Documentum user account and password form being displayed.
That concludes the overview of the out of the box working of the Documentum SiteMinder integration. The 2nd part of this article discusses a problem that manifests in compliance situations.
Lagging behind
March 11, 2011 at 7:34 pm | Posted in Architecture, Development | 1 CommentTags: documentum, grails, groovy
I’ve been spending some time with both Grails and Drupal (for different projects I would add). One of the things that really stands out and connects both of these (open-source!) technologies is their extensive use of plugins (or modules as Drupal calls them).
For both Grails and Drupal there is a highly functional core but there is always extra functionality you would like and often some-one has already written them.
The standouts of both systems is how easy it is to install the extra functionality. In Grails you would type the command:
grails install-plugin
The system downloads the plugin and installs it into your project. Given Grails’ dependency injection support it’s usually a simple task to get the basic plugin functionality working.
In drupal you have to download the module yourself , however there is an excellent catalogue on the drupal.org site that contains the download links, version information and documentation. Installation usually means unzipping the folder into the drupal modules folder. At this point the module is available in the administration console for configuration. The whole process is very neat and feels pretty seamless.
Documentum is a very powerful technology however I sense it will feel pretty clunky when I get back to it.
Chalk Talks, Great Idea
January 28, 2010 at 4:36 pm | Posted in Development | Leave a commentTags: Case Management, documentum, xCP
2 of the most noticeable features of last year’s Momentum were the focus on Case Management/xCP Platform and a greater emphasis on ‘execution’. Whilst you can find out about the first feature on EMCs own channels I’ll expand a bit on the ‘execution’.
EMC Documentum like so many other vendors has been pretty good at the ‘Big Things’ such as great new features, new platforms, incorporating new products and so on. But what’s more important to those of us who actually have to convince people to buy, install, run, support and maintain Documentum system is the ‘little things’. Little things like accurate and comprehensive documentation, Sample apps, and applications that are free of bugs.
It was apparent from a number of seminars at Momentum that all these ‘little things’ are being given greater emphasis in the CMA division. xCP itself is an outcome from such thinking. Previously we had a number of disparate products that were individually licensed (Process Engine, Task Space, Forms Builder and so on) and it wasn’t always clear how they should be combined to produce a usable application nor how much it would cost to licence.
With xCP we should get a more rationalised licence cost but even more importantly a platform that is focussed on a particular application paradigm, Case Management. As part of xCP there is a sample application, Grants Management, that allows you to easily get up to speed with xCP and play around with it. There is also a focus within the xCP product management team to provide some ‘jump start’ features such as a focus on use cases and making the product focus on particular Case Management categories. There is a lot of concentration on best practices and making it easy to understand the best way of fitting the vast feature set together.
In this Chalk Talk both of these good things are in evidence. It’s a short video snippet that shows how to use a particular feature of Forms Builder. It’s a great way of getting across a simple but regularly needed feature that has a few gotchas if you are trying to do this the first time on your own. Best thing is you can immediately try this out if you have the Grants Management sample application installed. More to come from EMC hopefully.
Why DocApps are bad
January 27, 2009 at 5:23 pm | Posted in Continous Integration, Development | 4 CommentsTags: Composer, Continuous Integration, docapp
A recent comment on one of my posts pointed out that you could script DocApp installs using an unsupported ant task. This is certainly a useful facility however it doesn’t overcome the basic problem with Documentum Application Builder and DocApps – they don’t integrate well with source code control systems that are used to maintain all the other code and artefacts needed to develop a working system.
Think how you probably develop code for your system. You probably store your source code in a repository (Visual SourceSafe, Subversion, CVS, etc.). You probably have integrations in your IDE to allow you to automatically checkout and checkin code. You probably build your code automatically from the source code system. This is is all fairly standard development practice (hopefully!).
If you are a little more advanced then maybe you also package and deploy your application automatically and you store automated tests in your source code control system. The tests would be automatically executed whenever you build and deploy from your souce code control system.
Basically the source code control system is the lynchpin of your whole development effort. Using version control and labelling you can see how different releases have progressed and maybe track where and when bugs were introduced.
DocApps sit completely outside of this setup, you are effectively using a development docbase as an alternative source code control system – without all the benefits of a properly featured SCC! In an ideal world all your Documentum configuration assets would live in the source code control system – that includes things like type definitions. Now all the source artefacts for your development live in one place. Hopefully this is exactly what Composer will allow you to do.
Error Patterns
January 27, 2007 at 2:19 pm | Posted in Development, Troubleshooting | Leave a commentConsider these 3 seemingly unrelated problems:
- I am getting [DM_API_E_NO_COLLECTION]error, should I increase max_collection_count?
- My query runs but only returns 20 rows when I know there is over 100. Increasing batch_hint_size enables me to process all the rows, but what should I set it to to ensure this always works?
- I raised a bug with Documentum support that LDAP Synchronization against AD only synced a maximum of 1000 users when we had 1500 users (this was back in the days of 5.2). Support provided a fix that synced a maximum of 2000 users. The error reappeared when we extended our testing to more than 2000 users.
All the proposed solutions probably weren’t the correct ones. In the first case the problem is most likely code that fails to close a collection. With java you should usually embed the close() call inside a finally block to ensure that close is called even after an exception. Other programming languages require similar protective measures. If your code really requires more than the default 10 collections you probably have an application design problem.
In the 2nd case the user is almost certainly running the query with DF_READ_QUERY/DF_EXECREAD_QUERY flag (readquery or execquery,c,T,… when using the API). The solution would be to run the code with the DF_EXEC_QUERY flag. batch_hint_size is a performance parameter, it should never be used to ‘fix’ functional problems.
The last one is a case of incorrect implementation of the Active Directory sync code. The Active Directory api uses a paging mechanism to optimise the transfer of query results across the network. The idea is to set the page to a suitable size and then loop on each fetch until there is no more data (The same idea as batch_hint_size in fact). The original simplistic implementation simply exited after the first batch.
What all these cases have in common is that the developer failed to correctly understand the programming APIs involved. Most APIs are more than a simple collection of function calls. They often have subtle nuances and a failure to appreciate and understand these nuances can lead to runtime bugs. It is often difficult to detect these bugs with testing as they will depend on specific scenarios not often met in development or testing environments. The most effective way to avoid these bugs is ensure that code is thoroughly reviewed by an appropriately experienced coder.
Dealing with yacc stack overflow
January 23, 2007 at 9:41 pm | Posted in Development | 6 CommentsThe ‘yacc stack overflow’ error usually occurs when sections of a DQL query contain too many tokens. The most typical example is something like the following:
select * from dm_document where object_name in ('first token','second token',...,'500th token')
If the number of items in the in list exceeds about 490 items a yacc stack overflow occurs. The solution is to split up the long list of tokens into a number of separate constructs. In the case of the example above:
select * from dm_document where object_name in ('first token','second token',...,'485th token') or
object_name in ('486th token',...,'500th token')
Blog at WordPress.com.
Entries and comments feeds.

You must be logged in to post a comment.