May 24, 2013 at 9:05 am | Posted in Architecture, Development | Leave a comment
Tags: authentication plugin, content server, documentum, Netegrity, single sign on, SiteMinder, SSO
This article introduces the motivation and architecture behind web-based Single Signon systems and Documentum’s SSO plugin. The 2nd part of the article will discuss limitations in the out of the box plugin and a customisation approach to deal with the issue.
Overview
For many users having to enter a password to access a system is a pain. With most enterprise users having access to multiple systems it’s not only an extra set of key presses and mouse clicks that the user can do without but often there are lots of different passwords to remember (which in itself can lead to unfortunate security issues – e.g. writing passwords on pieces of paper to help the user remember!).
Of course many companies have become keen on systems that provide single sign on (SSO). There are a number of products deployed to support such schemes and Documentum provides support for some of them. One such product is CA Site Minder – formerly Netegrity SiteMinder and much of the EMC literature still refers to it as such.
SiteMinder actually consists of a number of components; the most relevant to our discussion are the user account database and the web authentication front-end. SiteMinder maintains a database of user accounts and authentication features and exposes an authentication API. Web-based SSO is achieved by a web-service that provides a username/password form, processes the form parameters and (on successful authentication) returns a SSO cookie to the calling application.
Documentum’s SiteMinder integration consists of 2 components. A WDK component that checks whether a SSO cookie has been set and a Content Server authentication plugin that will use the SiteMinder API to check the authentication of a user name/SSO cookie authentication pair.
How it works
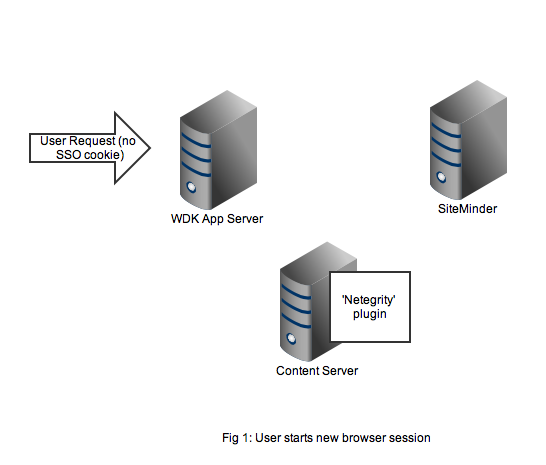
As usual it’s best to get an understanding by looking at the flow of requests and messages. Let’s take the case of a user opening a new browser session and navigating to a SSO-enabled WDK application (it could be webtop, web publisher or DCM). In Figure 1 we see a new HTTP request coming into the application server. At this point there is no SSO cookie and code in the WDK component can check this and redirect to a known (i.e. configured in the WDK application) SiteMinder service. I’ve also seen setups where the app server container itself (e.g. weblogic) has been configured to check for the SSO cookie and automatically redirect.
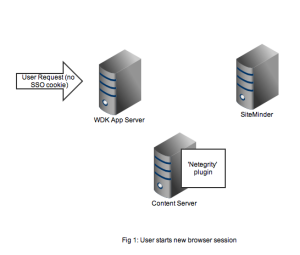
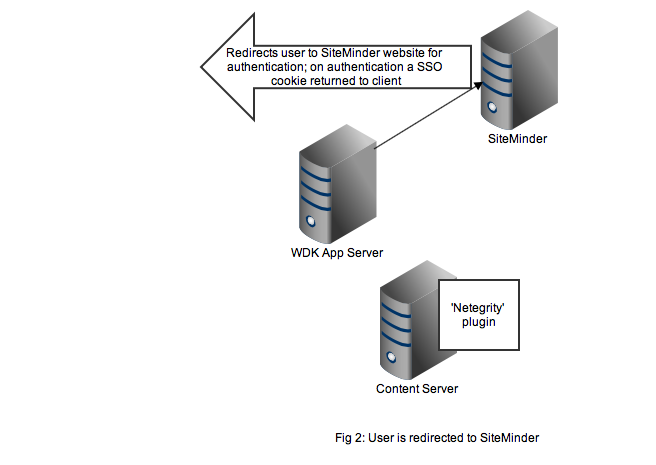
Redirection to the SiteMinder service will display an authentication form, typically a username and password but I guess SiteMinder also has extensions to accept other authentication credentials. As shown in Figure 2, on successful authentication the response is returned to the client browser along with the SSO cookie. Typically at this point the browser will redirect to back to the original WDK url. The key point is any subsequent requests to the WDK application will contain the SSO cookie.
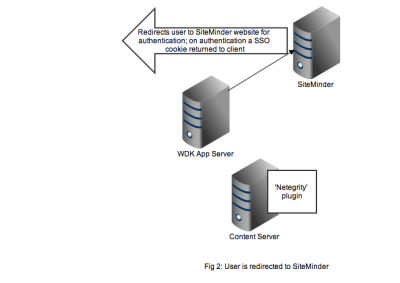
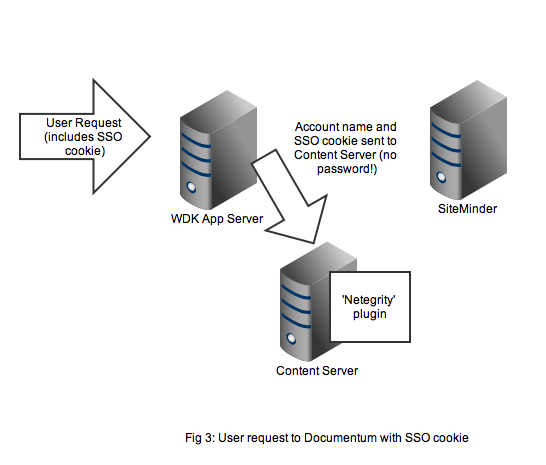
Any user that wants to perform useful work in a WDK application will need an authenticated Documentum session. In non-SSO Documentum applications our user would have to authenticate to the Content Server via a WDK username/password form. In SSO Documentum applications, if we need to authenticate to a Content Server (and we have a SSO cookie) WDK silently passes the username and SSO cookie to the Content Server. Our SSO-enabled Content Server will do the following:
- Look up the username in it’s own list of dm_user accounts
- Look to see that the user_source attribute is indeed set to ‘dm_netegrity’
- Passes the username and SSO token (i.e. the cookie) to the dm_netegrity plugin to check authentication
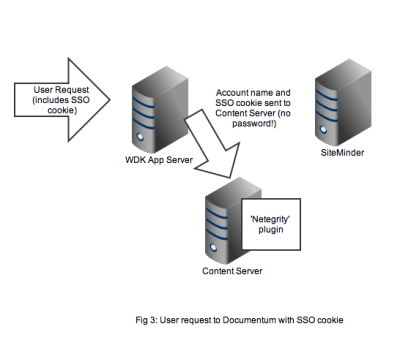
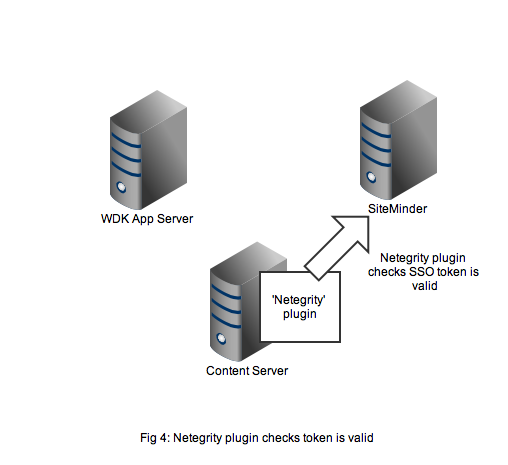
Figure 4 shows that the netegrity plugin will contact the SiteMinder service using the authentication API. The SiteMinder server confirms 2 things. First that the user account is indeed present in its database and secondly that the SSO token is valid and was issued for that user.
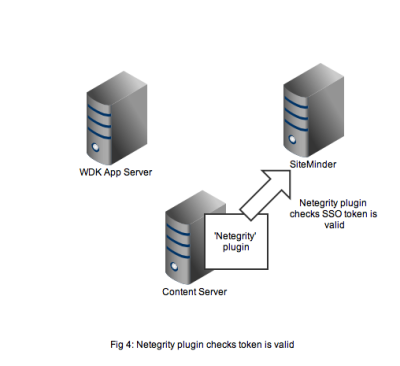
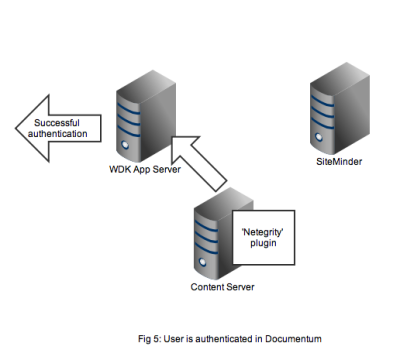
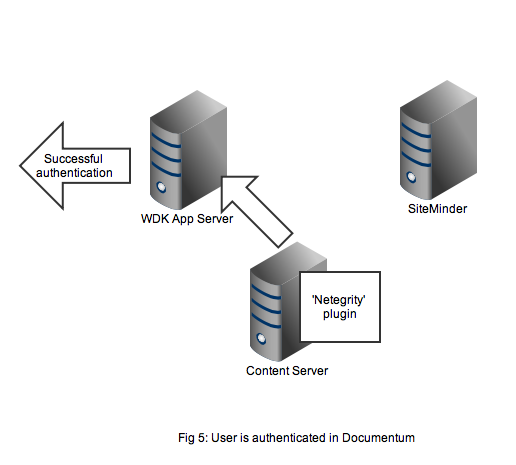
In Figure 5 we see that a successful authentication of the SSO token with SiteMinder means that the Netegrity plugin confirms authentication to the content server. A valid Documentum session will be created for the user and the user can continue to work. All without any Documentum user account and password form being displayed.
That concludes the overview of the out of the box working of the Documentum SiteMinder integration. The 2nd part of this article discusses a problem that manifests in compliance situations.
November 29, 2012 at 7:22 am | Posted in Architecture | 2 Comments
Tags: BOCS, branch office caching services, cloud, d2, documentum, emc, ondemand, xCP
I think EMC first started talking about On Demand at EMC World 2011. The idea is seductive and logical: rather than have to procure your own hardware, install and configure the software, and manage and administer the running system you get EMC to do it for you. The potential benefits are enormous.
First, economies of scale for running hardware in the same way as similar cloud-based offerings. By running on virtual machines and providing scale out options you potentially only have to pay for what you use.
Secondly, experts who can specialise in various aspects of installation, administration and troubleshooting. Furthermore there is an obvious incentive for EMC to focus on initiatives to simplify and automate tasks. Presumably that was the idea behind xMS, the deployment technology recently released with D7.
As a consequence of that last point it gives EMC a great way to collect usage data, bug information and performance insights.
Finally I see great potential in distributed content, allowing content to be replicated across data centres closer to the user. On-premise installations currently rely on solutions like BOCS or content replication to deliver better performance to users in remote offices. These can be tricky to configure without expert help and rely to a greater or lesser extent in having servers in locations where the organisation doesn’t want them.
So clearly I see big benefits, at least in theory. I have several thoughts around OnDemand some of which I hope to explore in future posts; in this post I want to talk about some potential drawbacks and how EMC might address them.
The first question people seem to ask is how will I be able to install and manage our customisations if EMC are managing everything? In fact I expect EMC to put significant limits on how much customisation you will be allowed in OnDemand environments. Which means that the arrival of xCP 2.0 with its ‘configure don’t code’ mentality (and D2s ui configurability) is serendipitous indeed. In fact I doubt OnDemand would really be workable for WDK-based apps like Webtop, DCM and Web Publisher; no-one runs these apps without considerable coded customisations.
Secondly, for some organisations moving content to the cloud will remain problematic as they will have regulatory requirements, or internal security needs, that mean certain types of content can’t reside in particular jurisdictions. This is by no means insurmountable and EMC will need plenty of distributed locations to satisfy some clients. However it does make the Amazon AWS model of ‘click and go’ server resourcing much more difficult for EMC.
Finally from a personnel perspective how will EMC deliver the necessary staffing of data centres if OnDemand really takes off? Running data centre operations is not a core business for EMC ( as far as I know). My assumption is that they won’t be building or running the hardware operations themselves but are partnering with existing companies that have the know how. However even setting up and staffing the software side is new to EMC. Does it have the existing capacity already or will it need to recruit? Or will much of OnDemand be farmed out to partners? Will they run 24×7 from the US or (more likely) use a follow the sun philosophy.
Time will obviously tell but I remain optimistic that OnDemand will be a success – it will depend heavily on the execution in what is a new area for EMC.
December 15, 2011 at 1:18 pm | Posted in Architecture | 1 Comment
Tags: documentum, PCS, print control services
This is the second part of a mini series of articles on Documentum Print Control Services (PCS) and how to use it effectively. The first part provided an introduction and overview of PCS. In this article I will take a much more in-depth technical look at the product.
PCS consists of a number of components:
- A DFS-based web service that is deployed on a JBoss application server
- A set of DARS that contain services that can be used by user-facing applications
- Optional WDK components for Webtop and Taskspace (as mentioned in the first article this PCS support is built into Documentum Compliance Manager)
As we will see later PCS also relies on PDF and Postscript rendition generation so DTS or ADTS is required.
So what happens when a controlled print request is issued from an application? The printing user-interface will usually collect some information from the user relating to the object to be printed. This will include the name of the printer and a reason for the print. Once the request is received by the application server control will be passed to the PCS ControlPrintService.requestPrint() function.
The requestPrint function does 3 things. First PDF Stamping Services (PSS) is used to create a watermarked copy of the main PDF rendition. I may cover PSS in more depth in another article, however the key point here is PSS takes an existing PDF rendition and generates a watermarked PDF that can include metadata overlaid in headers, footers or other areas of the document. PCS and PSS have tight integration where PSS exposes a Controlled Print-specific configuration and PCS can pass in Controlled Print attributes such as copy number, recipient and printing reason to be watermarked on the document.

Click to view in a new window
Next a dmc_pss_print_copy object is created in the repository. The watermarked PDF is the primary rendition for this object and the object is linked to the /Temp/PCSCopies folder. At this point the object’s print_status attribute is set to ‘Created’.

Click to view in a new window
Finally, a request for a Postscript rendition for the dmc_pss_print_copy object is made. The rendition will have a page_modifier of ‘PS4Print’. The server will wait for up to 2 minutes for the rendition to be generated and then return to the caller. Either way the print_status field is set to ‘PsRequested’. Up to now all the processing is synchronous, but now control is returned to the user of application.

Click to view in a new window
At this point the user is probably expecting the printer to output the printed document, however no print request has yet been sent to a printer, there is simply a dmc_pcs_print_copy object created possibly waiting for Postscript rendition to be created. There are 2 asynchronous task still required to be completed. First the Postscript rendition needs to be created:

Click to view in a new window
Of course it may have been created during the earlier synchronous processing but there is no guarantee. Continuous uninterrupted operation of controlled printing requires that your DTS or ADTS infrastructure is resilient, scalable and sized for all the rendition requests generated in a production environment. If your users have requested prints that don’t seem to be appearing your first port of call for troubleshooting is to confirm that DTS/ADTS is working and that Postscript renditions are being created for your dmc_pss_print_copy objects.
The Print Control Services server is ultimately responsible for sending your document to the required printer. Calling the Print Control Services server is the responsibility of the PcsAsyncPrintJob. For controlled print (and recall) requests to be completed in a reasonable amount of time this job needs to be set to run every couple of minutes and needs to be monitored for regular execution and successful job completion.
When PcsAsyncPrintJob runs it queries for all dmc_pss_print_copy objects that have print_status = ‘PsRequested’.

Click to view in a new window
For each dmc_pss_print_copy object the PCSAsyncPrintJob does the following:
- Ensures that a Postscript rendition has been created. If not no further processing is done on this execution of the job.
- Then calls the remote ControlPrintService DFS endpoint on the PCS server, calling the ‘print’ method.
Once the print request is received by ControlPrintService component the following happens:
- The audittrail is checked to ensure that the same document has not been printed with the requested copy number. If for some reason there is already an audittrail entry for this copy number an error is raised.
- The postscript file is sent to the printer using the Java Printing Service API.
- The service monitors the print job until completion (or failure) and then returns a response to the PcsAsyncPrintJob job.
- Creates an audittrail entry to record the controlled print

Click to view in a new window
The actual “printing” part of PCS is carried out using the Java Printing Services (JPS) API. If you are going to be making use of PCS in your organisation it may be worth your while getting to know the JPS a little better. I’ll discuss JPS in more depth in a later article. Once PCS has sent the document for printing it sets the print_status attribute to ‘PrintRequested’ – this is the last status update for the document. Note you only know that PCS has requested a print from the printer – there is no way for PCS to ‘know’ whether that print was successful and so it can not update the object further.
The key points to take away from this article are as follows:
- First, when the WDK application server returns control back to the user after a print request has been made there is no guarantee that the document has been sent to the printer. There are 2 layers of asynchronous processing required to print a document; depending on the speed, capacity and availability of the relevant servers it may take some time for the print to appear.
- Second the print may even not appear at all if there is a problem with one of the asynchronous components. This fact may not be obvious to the end user who may just assume that printing is “slow”.
December 5, 2011 at 1:31 pm | Posted in Architecture | 3 Comments
Tags: documentum, PCS, print control services
This is the first part of a mini series of articles on Documentum Print Control Services (PCS) and how to use it effectively.
Documentum PCS originated in the compliance products however from the 6.6 release it is a standalone product. If you haven’t worked in regulated environments before you may be a little unclear as to what its purpose is. PCS “controls” the printing of certain important documents, ensuring that a number of things happen when a “Controlled Print” takes place.
I’ll discuss the what first and then explain the why. First whenever a controlled print of a document is made that fact is recorded in the audit trail. A copy number is associated with the document and recorded in the audit trail entry; if you print another copy of the document then the copy number is incremented. In effect every print of a document is uniquely identified by object id and copy number. In fact PCS works in close tandem with Documentum PDF Stamping Services (PSS) to allow a watermark including the copy number to be overlayed on the printed document.
Additionally every printer in the organisation has to be added to the PCS configuration so controlled prints can only be made to well-known printers. Again the printer to which the print is sent is recorded in the audit trail.
Finally, subsequent to executing the controlled print, it may be necessary to record a ‘Recall’ of the print. A ‘Recall’ is recorded in the audit trail against a unique document print (the object id and copy number). The reasons for needing a recall maybe part of the operational lifecycle – one or more documents may have been superseded by an updated version and so all prints of the old version must be physically removed and that removal needs to be recorded. Alternatively it may simply be that a print was stuck in a printer or damaged or lost. It’s worth bearing in mind that when ‘Recalling’ a document with Documentum PCS the only thing that happens is that the recall is recorded in the audit trail as evidence and for reporting. PCS won’t, for example, halt print requests already sent to the printer.
A recall results in a notification sent to the inbox of interested parties. The recipient has to confirm acknowledgement of the notification, at which point a further audit trail entry is created. Thus there are 3 types of audit entry that can be created:
- On print
- On recall
- Recall confirmed
As pointed out in the comments both print and recall actions require the user to authenticate themselves before they are able to proceed.
So now we know what PCS does but it may not be clear why an organisation would need this functionality. As I alluded to earlier printing control is often used in regulated environments. Typical examples would be pharmaceutical or medical manufacturing, or aircraft production. These activities often take place in a factory or lab and need to follow defined and documented processes. Often this process documentation is physically printed, as online reference to the documentation is inconvenient or difficult.
In these types of scenario it is clearly essential that correct and up-to-date documentation is used by production staff (how happy would you be if certain components on the plane you are flying on were manufactured using out-of-date processes?). Not only does it make sense for management in these organisations to know there is a process to record what documentation is in use and when it is updated but in many cases regulatory authorities will required evidence that such systems are in place and demonstrated to work.
Given the above it is unsurprising that this functionality originated in the Documentum Compliance Manager (DCM) product. In earlier versions of DCM watermarking and print control were achieved using integrations with Liquent’s PDF Aqua products. However PCS was introduced as part of DCM 6.5 sp1 and became a separate product in 6.6. Controlled Print and Recall functions are provided as part of the DCM user interface but the latest release of PCS product comes with components that can be installed in the Webtop and Taskspace interfaces. This is part of EMCs policy of moving compliance functionality into the core stack and making it available to all clients rather than retaining a dependency on specialised interfaces. No doubt these features will be available in the C6 products at a later date.
The next installment will dig into the guts of the PCS architecture to see how it works.
Update (14 Dec 2012): I wonder where the new Life Sciences products announced with D7 will fit in with PCS? Will they use PCS and PSS or is there some other technology to do this?
March 11, 2011 at 7:34 pm | Posted in Architecture, Development | 1 Comment
Tags: documentum, grails, groovy
I’ve been spending some time with both Grails and Drupal (for different projects I would add). One of the things that really stands out and connects both of these (open-source!) technologies is their extensive use of plugins (or modules as Drupal calls them).
For both Grails and Drupal there is a highly functional core but there is always extra functionality you would like and often some-one has already written them.
The standouts of both systems is how easy it is to install the extra functionality. In Grails you would type the command:
grails install-plugin
The system downloads the plugin and installs it into your project. Given Grails’ dependency injection support it’s usually a simple task to get the basic plugin functionality working.
In drupal you have to download the module yourself , however there is an excellent catalogue on the drupal.org site that contains the download links, version information and documentation. Installation usually means unzipping the folder into the drupal modules folder. At this point the module is available in the administration console for configuration. The whole process is very neat and feels pretty seamless.
Documentum is a very powerful technology however I sense it will feel pretty clunky when I get back to it.
January 20, 2011 at 4:03 pm | Posted in Architecture, Performance | 2 Comments
Tags: fast, fulltext, HA, High Availability
The installation of FAST Search in high availability mode is pretty well covered in the Installation and Administration documentation (see Powerlink for the documentation). However the details of administration tasks for HA setups is not so good and it is easy to mess up an installation if you are not careful. It helps to have some understanding of the configuration objects involved.
When you install the basic FAST setup, assuming for the sake of simplicity that we are only indexing 1 repository, you will have a machine containing an Index Server and an Index Agent. The Index Agent is the component that communicates with the Content Server to retrieve content that needs to be indexed. The Index Agent passes indexable content to the Index Server; the Index Server actually builds and maintains the indexes and responds to search requests.
After running the Index Server installation and Index Agent configuration for a repository you have an Index Server and Index Agent installed and running on the indexing machine and 3 configuration objects in the repository. The 3 objects represent the Index, the Index Server and the Index Agent respectively and are related as shown in the diagram.

The 3 objects are created every time the index configuration program is run. In particular the following attributes are always set as follows:
| Object |
Attribute |
Value |
| dm_fulltext_index |
index_name |
repository_ftindex_01 |
| dm_fulltext_index |
is_standby |
0 |
| dm_ftindex_agent_config |
index_name |
repository_ftindex_01 |
| dm_ftindex_agent_config |
queue_user |
dm_fulltext_index_user |
| dm_ftengine_config |
object_name |
FAST Fulltext Engine Configuration |
In a high availailability configuration you have another machine with an installed Index Server and Index Agent configuration. There will also be another 3 objects that define the second Index Server/Agent configuration. So how does the installation of a secondary index work?
Before running the 2nd Index Server install/Index Agent configuration program you need to run the HAPreInstall script. The script has the following effect on the 3 existing configuration objects:

Now the Index Server install/Index Agent configuration can be run on the 2nd machine resulting in 3 new objects (the original 3 objects are shown as shaded objects). Note that the 3 new objects have exactly the same attributes as for a ‘Basic’ installation. The Index Agent configuration program seems to have no ‘knowledge’ of whether it is running Basic or HA setup, it simply creates the same objects each time. The HAPreInstall and HAPostInstall scripts have the ‘intelligence’ to adjust the various configuration objects.

Finally you need to run the HAPostInstall script which makes the following changes:

Click on the table below to see the key attributes on these objects and how they appear in Basic and HA modes:

December 3, 2008 at 10:26 pm | Posted in Architecture, D6, Momentum | 7 Comments
Tags: Composer, Continuous Integration
Ever since I got back from Momentum it’s been work, work, work. That’s what happens when you take 4 days off to look around at what’s going on. I recall that I was going to post some more thoughts on some of the other products that I saw.
I went to David Louie’s presentation on Composer. Have to say I was impressed with what I saw. This maybe because I’ve been developing with Eclipse for a while now, so having something that integrates natively with this environment is a big plus. Whilst there are many interesting functional features of Composer I was most interested in a single slide that compared Composer with Application Builder.
First Composer doesn’t require a connection to the docbase to get your work done. You can of course import objects from a docbase, but you can also import from a docapp archive.
Secondly Composer can install your application (a DAR, similar to a DocApp in concept) into a docbase via a GUI installer but you can also use something called Headless Composer which is a GUI-less installer that runs from the command line. Not absolutely sure on the specifics at this point but possibly uses ant. David said that there are details in the documentation – I will be sure to try it out and post my findings at a later date.
This last point was of great interest to me as I’m currently investigating how to run Documentum development using a continuous integration approach. Being able to deploy your artifacts from the command line, and therefore from some overall automated controlling process is essential to making continuous integration a reality. On this note I also spoke to Erin Samuels (Sharepoint Product Manager) and Jenny Dornoy (Director, Customer Deployments). I hope that the sharepoint web parts SDK that is likely to integrate into MS Visual Studio will also have support for a headless installer, and also that Documentum/EMC products generally support the continuous integration approach.
November 13, 2008 at 8:26 am | Posted in Architecture, D6, Momentum, Performance | 2 Comments
Tags: Advanced Site Caching Services, Momentum, XML Store
On Tuesday and Wednesday I attended a load more sessions covering XML Store, Centrestage, Composer, Sharepoint and Web Content Management. In the next few posts I’ll share some of my thoughts and impressions, starting with XML Store.
For those that don’t know, EMC purchased a company called X-hive a while back. X-hive have an XML database product and that has now been integrated into the full Content Server stack. The easiest way to picture this is to take the old picture of the repository as consisting of a relational database and a file system and add in a third element, the XML Store.
From 6.5 (possibly sp1, I don’t remember) all XML is stored in the XML store. The XML Store is built around the many XML standards that are in existence such as XQuery, XSL and the XML full-text query standard.
The XML is not stored in the usual textual XML format but in a DOM format. This presumably is to allow them to implement various types of index and to optimise the query access patterns. The performance claims for the database are impressive although they need to be taken with a pinch of salt. As with all benchmarking, vendors will target specific goals in the benchmark. However your real-life workloads could be very different. If you are expecting high-throughput for an application using the XML store I suggest you put some work into designing and executing your own benchmarks.
In addition to indexes there is also a caching facility. This was only talked about at a high-level, however just as relational database performance experts made a career in 1990s out of sizing the buffer cache properly so we may see something similar with XML database installations. We may see them suffering poor performance as a result of under-sized hardware and mis-configuration. As always don’t expect this to just work without a little effort and research.
One other point I should make is that the XML Store is not limited to the integrated Content Server implementation. You can also install instances of XML Store separately. For example the forthcoming Advanced Site Caching Servicees product provides for a WebXML target. This is essentially an XML Store database installed alongside the traditional file system target that you currently get with SCS. You can then use the published XML to drive all sorts of clever dynamic and interactive web sites.
November 11, 2008 at 4:22 pm | Posted in Architecture, D6, Momentum | 2 Comments
Tags: documentum 6, momentum 2008, sharepoint
All this week I am at Momentum in Prague. It’s a great opportunity to catch up with Documentum employees, partners and users, and also to see what is going in the Documentum world.
I arrived yesterday morning, and attended the Sharepoint Integration product advisory forum. The forum was run by Erin Samuels and Andrew Chapman. The session centred around a number of topics relating to Sharepoint-Documentum integration.
First of all there was a round-table on the kind of integration scenarios people were facing. Interestingly, and reassuringly, there seem to be far fewer ‘maverick’ implementations as Andrew called them. Maverick implementations are where sharepoint is installed as a generic application that can be just configured and used by any department and team without any kind of guidance or direction from IT. This leads to silos of information and lack of control of any kind over the information. Whilst departments like this quick and easy delivery of applications it stores up problems for the organisation as it is no longer able to utilise or manage enterprise-wide data.
Andrew then talked about a new product that is due to come out called Journalling. Whilst I don’t think the naming is great (maybe that’s not how it is going to be sold but it was certainly the name used for the technology) the principle was very powerful. It uses the Microsoft-provided Sharepoint EBS interface to allow you to redirect where sharepoint stores its data. By default sharepoint will store content and metadata in a SQL server database. Each sharepoint instance will require a sql server instance (apparently) and this can easily become a big data management problem. Furthermore as sql server stores all content as BLOBs (Binary Large OBjects) there can be scalability issues.
With Documentum EBS implementation, content is (transparently to the user) stored in a Documentum repository rather than SQL server (there is just a ‘journal’ entry in sharepoint representing the object). This provides all kinds of useful benefits such as being able to leverage Documentum’s data storage scalability, EMC hierachical storage management, de-deduplication and so on.
At this point there was a big discussion around a point introduced by Andrew. Since the data is now stored in Documentum we can access it via Documentum clients; for example you average user might be creating content in sharepoint across the organisation, but you have power users who need the full power of Documentum interfaces to work with the data. But what operations should documentum clients be allowed on sharepoint originated data? Read or other types of operation that don’t modify the content/metadata are fine, but should we allow update or delete access? If yes then there is additional work required as right now an update outside of sharepoint would cause sharepoint to throw an error the next time a user accesses the object. Predictably there was an almost equal 3-way split over who wanted no Documentum access, read-only/no-modify access and total control.
Later on I got to meet up with some people that I only know from the Documentum forums and blogs: Johnny Gee, Erin Riley and Jorg Kraus. It was great to finally get to speak to these guys after years of interacting over the web.
February 29, 2008 at 9:19 pm | Posted in Architecture, Performance | 1 Comment
Well so far 2008 has been incredibly busy. I’ve been involved with putting a major project live whilst also completing work on the new Xense Profiler for DFC. What with trying to have a life outside work that has left me with very little time to look at the support forums or to post here. Hopefully I’ll have a bit more time from March onwards.
Anyway February was looking a little empty so here’s a small thought. I’ve been spending time recently thinking about system availability. Now traditionally when you ask systems people to start thinking about these sorts of issues they immediately start thinking of resilience, load-balancing and clustering solutions. Now these definitely have their place but it’s useful to step back a bit and think about what we are trying to achieve.
What is availability?
If you look for a definition in a text book or somewhere on-line you are likely to find something similar to the following:
Availability is a measure of the continuous time a system is servicing user requests without failure. It is often measured in terms of a percentage uptime, with 100% being continously available without failure.
In reality 100% isn’t possible and you will see requirements quoted in terms of 99%, 99.9%, 99.99% and so on. The mythical uptime requirement is usually the ‘5 nines’ 99.999%, which works out at around 5 minutes per year. If you find yourself being asked for this then the requesting department had better have deep pockets.
Causes of unavailability
Behind this apparently clear and simply definition are a load of questions. If you think about it there are all sorts of reasons why a service could be unavailable:
- Failure of a hard disk
- Network failure
- Operating system os crash
- Software bug
- Operator error (I usually call this the ‘del *.*’ problem)
Which of these could be protected by resilience? The first 3 could probably be solved by:
- hardware resilience (RAID)
- load-balancing and resilient network infrastructure
- clustering
But what about the last 2? Most of the schemes mentioned above operate below the application layer. So problems like software bugs are not likely to be solved by load-balancing or clustering. In general these sort of problem need to be addressed by a monitoring and alerting system.
Operator errors, of course, are rather more difficult to cope with. Hopefully you have an adequate Disaster Recovery procedure that minimises the damage although in certain situations you are likely to lose some data. Even so typical Disaster Recovery procedures usually start in terms of hours possibly extending for days in the worst case scenario. As usual the more money you spend the lower the impact on the availability target.
So which of these is the most common. I would bet that the last one (the one it is most difficult to sucessfully protect against) is far more common that you might think. This is certainly the of view of Hennessy and Patterson in their book Computer Architecture: A Quantitative Approach.
Parting words
Well it’s nearly my dinner time so I have promised my long suffering family to finish here. When presented with those bland ‘the system must be available for xx.xxx%’ requirements make sure you (and more importantly your customer/business) realise the implications of what they are asking for.
Next Page »


You must be logged in to post a comment.