Using the Spark Event Timeline
September 8, 2015 at 1:42 pm | Posted in Performance | Leave a commentSource: Using the Spark Event Timeline
New Blog
March 4, 2015 at 10:59 pm | Posted in Performance | Leave a commentI have just published the first post on my new blog, Machine Learning at Speed. I left the world of EMC Documentum mid-2013 to concentrate on my other technical interests: Hadoop, data science and machine learning. If you’ve enjoyed Inside Documentum please consider following my posts on the new site – I believe that data science and machine learning will finally allow us to fulfil the promise of true knowledge discovery that content management promised for so long.
Documentum on PostgreSQL
September 17, 2013 at 3:53 pm | Posted in Performance | Leave a commentTags: database, documentum, Greenplum, machine learning, NLP, postgres
Great news from Lee Dallas reporting from the Documentum Developer Conference: Documentum Developer Edition is back and now runs on PostgreSQL. I discussed this a few months back and I thought that maybe EMC didn’t have the stomach for something so technical, but I was wrong. So kudos to EMC.
Lee mentions it’s not yet production ready, so hopefully that is in the pipeline. After that how about certifying it to run on Greenplum, EMC’s massively scalable PostgreSQL. Then the sky is the limit for large-scale NLP and machine learning tasks. For example last year I wanted to run a classification algorithm on document content to identify certain types of document that couldn’t be found by metadata. There are plenty of other uses I can think.
I’ll be downloading the edition as soon as possible to see how it runs.
Running ADMM LASSO example on Mac OS X Mountain Lion
July 5, 2013 at 2:13 pm | Posted in Big Data | Leave a commentTags: ADMM, Classification, LASSO, Lion, Mac OS X, machine learning, Mountain Lion, Regression
Being able to process massive datasets for machine learning is becoming increasingly important. By massive datasets I mean data that won’t fit into RAM on a single machine (even with sparse representations or using the hashing trick). There have been a number of initiatives in the academic and research arena that attempt to address the problem; one very interesting one is Alternating Direction Method of Multipliers (ADMM). It’s an old idea that has been resurrected in this paper by Stephen Boyd’s team at Stanford. A quick google on ‘Alternating Direction Method of Multipliers’ shows a recent surge of academic papers as people have started to take the ideas on-board.
That paper comes with some example code including a complete small-scale example of distributed L1 regularized least squares using MPI. The code was tested on Mac OS X 10.6, Debian 6, and Ubuntu 10.04. It requires installation of an MPI implementation but the authors state that OpenMPI is installed with Mac OS X 10.5 and later. So it sounds like it would be easy to run on my new iMac. Well it turns out that from Mac OS X 10.7 (Lion) this is no longer true (see here). So here are the augmented instructions for Mac OS X 10.8 that worked for me; they come with the usual ‘your mileage may vary’ caveat.
Before You Start
I assume that XCode is already installed (freely available from the App Store, i’m using 4.6.3) and that command line tools are installed (Xcode | Preferences | install Command Line Tools). Typing gcc in the terminal gives me
i686-apple-darwin11-llvm-gcc-4.2.
You should, of course, always download from a reputable site and verify the checksum (e.g. using md5 or gpg). Safari seems to be set up to automatically uncompress .tar.gz files to .tar. Very helpful Safari but now I can’t checksum the downloaded file! To prevent this behaviour go to Safari | Preferences | General tab and untick ‘Open “safe” files after downloading’. Yes I found that ironic too.
Install GNU Scientific Library
First you need to download and install GNU Scientific Library. I used the mirror suggested by the GSL site. Download the latest release which in my case was 1.15 (gsl-1.15.tar.gz). Now do the following
tar zxf gsl-1.15.tar.gz mv gsl-1.15 ~ cd ~/gsl-1.15 export CC=CLANG ./configure make make check > log 2>&1
The ‘make check’ call runs some tests on the installation. Originally I didn’t have the export CC=CLANG line and this failed some of the tests so it seems worthwhile to do the checks.
So review the file called log and if everything looked like it passed and no failures, proceed as follows:
sudo make install
This will place GSL in /usr/local and requires admin privileges. You should be able to use make –prefix to put it elsewhere but I didn’t try that.
Install OpenMPI
Go to http://www.open-mpi.org and download the latest stable release of Open MPI – at the time of writing that was 1.6.5. Then the following sequence will install (again i’m installing to /usr/local):
tar zxf openmpi-1.6.5.tar.gz mv open-1.6.5 ~ cd ~/open-1.6.5 ./configure --prefix /usr/local make sudo make install
Download and Run Distributed LASSO
The link to the ADMM source code is on the page ‘MPI example for alternating direction method of multipliers‘ along with instructions for installing:
- Download and expand the mpi_lasso tar ball. The package contains a Makefile, the solver, and a standard library for reading in matrix data.
- Edit the Makefile to ensure that the GSLROOT variable is set to point to the location where you installed GSL, and that the ARCH variable is set appropriately (most likely to i386 or x86_64). On some machines, it may be necessary to remove the use of the flag entirely.
- Run make. This produces a binary called lasso.
Incidentally the Makefile seems to contain additional instructions to build a component called ‘gam’. gam.c is not included in the download so I just removed all references to gam. Here is what my Makefile looks like:
GSLROOT=/usr/local # use this if on 64-bit machine with 64-bit GSL libraries ARCH=x86_64 # use this if on 32-bit machine with 32-bit GSL libraries # ARCH=i386 MPICC=mpicc CC=gcc CFLAGS=-Wall -std=c99 -arch $(ARCH) -I$(GSLROOT)/include LDFLAGS=-L$(GSLROOT)/lib -lgsl -lgslcblas -lm all: lasso lasso: lasso.o mmio.o $(MPICC) $(CFLAGS) $(LDFLAGS) lasso.o mmio.o -o lasso lasso.o: lasso.c mmio.o $(MPICC) $(CFLAGS) -c lasso.c mmio.o: mmio.c $(CC) $(CFLAGS) -c mmio.c clean: rm -vf *.o lasso
A typical execution using the provided data set and using 4 processes on the same machine is
mpirun -np 4 lasso
The output should look like this:
[0] reading data/A1.dat [1] reading data/A2.dat [2] reading data/A3.dat [3] reading data/A4.dat [3] reading data/b4.dat [1] reading data/b2.dat [0] reading data/b1.dat [2] reading data/b3.dat using lambda: 0.5000 # r norm eps_pri s norm eps_dual objective 0 0.0000 0.0430 0.1692 0.0045 12.0262 1 3.8267 0.0340 0.9591 0.0427 11.8101 2 2.6698 0.0349 1.5638 0.0687 12.1617 3 1.5666 0.0476 1.6647 0.0831 13.2944 4 0.8126 0.0614 1.4461 0.0886 14.8081 5 0.6825 0.0721 1.1210 0.0886 16.1636 6 0.7332 0.0793 0.8389 0.0862 17.0764 7 0.6889 0.0838 0.6616 0.0831 17.5325 8 0.5750 0.0867 0.5551 0.0802 17.6658 9 0.4539 0.0885 0.4675 0.0778 17.6560 10 0.3842 0.0897 0.3936 0.0759 17.5914 11 0.3121 0.0905 0.3389 0.0744 17.5154 12 0.2606 0.0912 0.2913 0.0733 17.4330 13 0.2245 0.0917 0.2558 0.0725 17.3519 14 0.1847 0.0923 0.2276 0.0720 17.2874 15 0.1622 0.0928 0.2076 0.0716 17.2312 16 0.1335 0.0934 0.1858 0.0713 17.1980 17 0.1214 0.0939 0.1689 0.0712 17.1803 18 0.1045 0.0944 0.1548 0.0710 17.1723 19 0.0931 0.0950 0.1344 0.0708 17.1768 20 0.0919 0.0954 0.1243 0.0707 17.1824 21 0.0723 0.0958 0.1152 0.0705 17.1867 22 0.0638 0.0962 0.1079 0.0704 17.1896 23 0.0570 0.0965 0.1019 0.0702 17.1900 24 0.0507 0.0968 0.0964 0.0701 17.1898 25 0.0460 0.0971 0.0917 0.0700 17.1885 26 0.0416 0.0973 0.0874 0.0699 17.1866 27 0.0382 0.0976 0.0834 0.0698 17.1846 28 0.0354 0.0978 0.0798 0.0697 17.1827 29 0.0329 0.0980 0.0762 0.0697 17.1815 30 0.0311 0.0983 0.0701 0.0696 17.1858 31 0.0355 0.0985 0.0667 0.0696 17.1890
If you open up the file data/solution.dat it will contain the optimal z (which equals x) parameters, most of which should be zero.
Documentum and Databases
July 3, 2013 at 4:11 pm | Posted in Performance | 4 CommentsTags: documentum, Greenplum, postgres
Here’s a quick thought on Documentum and databases. For a long time Documentum used to support a variety of databases however these days support is just for 2 in D7 (Oracle and SQL Server) down from 4 in D6.7 (the previous 2 plus DB2 and Sybase).
The clear reason for narrowing down the choice of database server is (I suspect) the cost of developing for and supporting a large number of choices, particularly since most of the database/OS combinations were used by only a handful of customers.
So why doesn’t EMC port the application to postgres and cut that choice down to 1? Why postgres? Well because EMC owns Greenplum (well actually it’s now part of Pivotal but that just complicates the story) and Greenplum is an enhanced postgres.
The logic for this is clear: EMC would like people to move to OnDemand and it makes sense for them to have ownership of the whole technical stack. At the very least they must be shelling out money to one of the database vendors. I’m not sure which one – if you have access to an OnDemand installation try running ‘select r_server_version from dm_server_config’ and see what’s returned, someone let me know the results if you could.
There are a couple of reasons why EMC might be reluctant. First it’s a big change and people (including EMCs own development and support teams) have a big skills base in the legacy databases. Taking a medium-term strategic view this is not a great reason and is just a product of FUD – Documentum has taken brave technical steps in the past such as eliminating the dmcl layer with great success.
Second we’ve been hearing a lot over the last few years about the NG server that runs on XHive xml database that is touted to replace the venerable Content Server in the longer term. Perhaps EMC is reluctant to work on 2 such radical changes.
Who knows? It’s just a thought …
Customising Documentum’s Netegrity Siteminder SSO plugin pt 2
July 1, 2013 at 9:51 am | Posted in Performance | Leave a commentTags: Documentum DCM, Netegrity, single sign on
The 1st part of this article introduced the motivation and architecture behind web-based Single Signon systems and Documentum’s SSO plugin. This 2nd part of the article discusses limitations in the out of the box plugin and a customisation approach to deal with the issue.
Sometimes you don’t want SSO
Whilst SSO is a great boon when you just want to login and get on with some work there are situations when it is positively unwanted. A case in point is electronic sign off of documents in systems like Documentum Compliance Manager (DCM). The document signoff screens in DCM require entry of a username and password (a GxP requirement) yet the out-of-the-box netegrity plugin only understands SSO cookies, it doesn’t know what to do with passwords.
Inside the plugin
Before looking at the solution let’s look in detail as how the out-of-the-box plugin works. When the dm_netegrity plugin receives an authentication request it contacts the SiteMinder application via the SiteMinder Agent API (SiteMinder libraries are included with the Content Server installation). The following API calls are made to the SiteMinder server:
-
Sm_AgentApi_Init(). Sets up the connection to the SiteMinder server.
-
Sm_AgentApi_DoManagement(). “Best practice” call to the SiteMinder server passing an authentication agent identifications string: Product=DocumentumAgent,Platform=All,Version=5.2,Label=None.
-
Sm_AgentApi_DecodeSSOToken(). Passes the SSO token to SiteMinder to confirm that the token is valid i.e. that it has been produced by that SiteMinder infrastructure. If the call returns a success code then the token is valid. A session specification is also returned to the calling program – this is the identifier that connects the SSO token to the session originally created on the SiteMinder infrastructure.
-
Sm_AgentApi_IsProtected(). Checks whether SiteMinder regards the web application context as a protected resource. This call is probably needed to fill in a data structure that is used in the in the next call.
-
Sm_AgentApi_Login(). One of the input parameters to this call is the session specification (from step 3). If the session specification is passed then SiteMinder will will do some verification checks on the session (has it expired? is the user active?) and then return the user LDAP identifier. The plugin uses this information to check that the token is for the correct user.
Solution
The out of the box (OOB) dm_netegrity plugin provided by EMC is setup to authenticate users who have previously authenticated against SiteMinder and received an SSO token in their browser session. In our case, where authentication with a username and password is required, there is no support in the DCM application for re-authenticating against the SiteMinder SSO solution. Where such authentication is attempted the OOB plugin will return an authentication failure as it is not designed to authenticate usernames and passwords against SiteMinder.
One way to solve this problem is to add support in the authentication plugin for authenticating against a username and password as well as a SSO token. Since SSO tokens are very large (several hundreds of characters) whilst passwords are generally significantly smaller, we can use the length of the authentication token to decide whether the token is an SSO credential or a password. In practice something like 20 characters is a good cutoff point. If the length is greater than this limit it is treated as an SSO credential and processed as described above. If the length is 20 characters or less it is treated as a password and processed using the following API calls.
-
Sm_AgentApi_Init(). Sets up the connection to the SiteMinder server.
-
Sm_AgentApi_DoManagement(). “Best practice” call to the SiteMinder server passing an authentication agent identifications string: Product=DocumentumAgent,Platform=All,Version=5.2,Label=None.
-
Sm_AgentApi_IsProtected(). Checks whether SiteMinder regards the web application context as a protected resource.
-
Sm_AgentApi_Login(). Since Sm_AgentApi_DecodeSSOToken() has not been called no session specification is available and is not passed into the Login call (compare the out-of-the-box logic). However if the username and password are passed to the Login function SiteMinder will validate the credentials. If a success return code is received the user is authenticated, otherwise the user is not authenticated.
Implementation and Deployment
Source code for the out of the box plugin is provided in the Content Server installation. It is written in C++ and has a makefile that covers a number of operating systems. To get this to work for 64-bit Linux took a little manipulation of the compiler and linker options.
The customisation should be deployed as a single *nix shared library. When the file is deployed to $DOCUMENTUM/dba/auth on the Content Server it is available as a dm_netegrity plugin (after a Content Server restart).
Note: the out-of-the-box dm_netegrity_auth.so library must not be present in the auth directory as this will cause a conflict when the plugins are loaded by Content Server and both try to register themselves as ‘dm_netegrity’.
Conclusion
The solution is fairly simple in concept, the devil is in the details of compile/link, deployment and testing. If you think you need to implement customised SSO for your project and want some help designing and implementing your solution please contact me for consulting work – initial advice is not charged.
Hadoop and Real-time Processing
June 21, 2013 at 8:50 am | Posted in Performance | Leave a commentTags: Architecture, Big Data, Hadoop, Hidden Markov Model, Kafka, Mahout, Real-time, Storm
Almost since the day that Hadoop became big news some people have been predicting the demise of the system. I have heard several different flavours of this argument one being that what is needed is ‘real-time’ big data analytics and that Hadoop with its batch processing and CPU hungry data-munching is not fit for the task. I think this misunderstands the role that Hadoop is and will continue to play in any big data analytics system. In many cases batch oriented applications (often based on Hadoop and its various ecosystem products) will do the big data crunching and CPU-hungry work offline, under non-realtime constraints. Models and output then feeds into real-time systems that are able to process real-time data through the model.
A paper by Bhattacharya and Mitra called Analytics on Big FAST Data Using a Realtime Stream Data Processing Architecture on the EMC Knowledge Sharing site provides a great example of how this offline/real-time combination works. I believe this will become an archetype for how such systems should be built.
Not only do they show how event collection (Apache Kafka), batch model building (Hadoop/Mahout) and Real-time processing (Storm) can work together but they also provide a very accessible introduction to Hidden Markov Models using a couple of characters called Alice and Bob. With a 60% chance of rain Bob clearly lives in the UK. Probably somewhere near Manchester.
Edit 20 Dec 2016: Seems that link has disappeared. If you search for the paper you should be able to find a copy e.g. http://docplayer.net/1475672-Analytics-on-big-fast-data-using-real-time-stream-data-processing-architecture.html
Data Science London Meetup June 2013
June 14, 2013 at 2:08 pm | Posted in Performance | Leave a commentTags: Big Data, Cloudera, data science, Data Science London, Doug Cutting, Ian Ozsvald, Knime, machine learning, NLP, Scraper Wiki
This is a quick post to record my thoughts and impressions from the Data Science London meet up I attended this week. We were treated to 4 presentations on a variety of Data Science/Machine Learning/Big Data topics. First up was Rosaria Silipo from Knime. Knime is new to me, it’s a visual and interactive machine learning environment where you develop your data science and machine learning workflows. Data sources, data manipulation, algorithm execution and outputs are nodes in a eclipse-like environment that are joined together to give you an end-to-end execution environment. Rosaria took us through a previous project showing how the Knime interface helped the project and showing how Knime can be extended to integrate other tools like R. I like the idea and would love to find some time to investigate further.
Next up was Ian Hopkinson from Scraperwiki talking about scraping and parsing PDF. Ian is a self-effacing but engaging speaker which made the relatively dry subject matter pretty easy to digest – essentially a technical walkthrough on implementing the extraction of data from 1000s of PDFs, warts and all. 2 key points:
- Regular Expressions are still a significant tool in data extraction. This is a dirty little secret of NLP that I’ve heard before. Kind of depressing as one of the things that attracted me to machine learning was the hope that I might write less REs in the future
- Scraperwiki are involved in some really interesting public data extraction for example digitizing UN Assembly archives. Don’t know if anyone has done analysis of the UN voting patterns on a large-scale but I for one would be interested to know if they correlate with voting on Eurovision Song Contest
Third up was Doug Cutting. Doug is the originator of Lucene and Hadoop which probably explains the frenzy to get into the meeting (I had been on the waiting list for a week and eventually got the a place at 4.00 for a 6.30 start) and the packed hall. Doug now works for the Hadoop provider Cloudera and was speaking on the recently announced Cloudera Search. Cloudera Search enables Lucene indexing of data stored on HDFS with index files stored in HDFS. It has always been possible (albeit a bit fiddly) to do this however there were performance issues. Performance issues were mostly resolved by adding a page cache to HDFS. They also incorporated and ‘glued-in’ some supporting technologies such as Apache Tikka (extracts indexable content out of multiple document formats like word, excel, pdf, html), Apache Zookeeper and some others that I don’t remember. A really neat idea is the ability to index a batch of content offline using MapReduce (something MapReduce would be really good at) and then merge the off-line index into the main online index. This supports use cases where companies need to re-index their content on a regular basis but still need near real-time indexing and search of new content. I can also see this being great for data migration type scenarios. All in all I think this is fascinating and it will be interesting to see how the other Hadoop providers respond.
Last up was Ian Ozsvald talking about producing a better Named Entity Recogniser (NER) for brands in twitter-like social media. NER is a fairly mature technology these days however most of the available technology is apparently trained on more traditional long-form content with good syntax, ‘proper’ writing and with an emphasis on big (often American) brands. I particularly applaud the fact that he has only just started the project and came along to present his ideas and to make his work freely available on githup. I would love to find the time to download it myself and will be following his progress. If you are interested I suggest you check out his blog posting. As an aside he also has a personal project to track his cat using a raspberry Pi, which you can follow on twitter as @QuantifiedPolly.
All in all a great event and thanks to Carlos for the organisation, and the sponsors for the beer and pizza. Looking forward to the next time – assuming I can get in.
Customising Documentum’s Netegrity Siteminder SSO plugin pt 1
May 24, 2013 at 9:05 am | Posted in Architecture, Development | Leave a commentTags: authentication plugin, content server, documentum, Netegrity, single sign on, SiteMinder, SSO
This article introduces the motivation and architecture behind web-based Single Signon systems and Documentum’s SSO plugin. The 2nd part of the article will discuss limitations in the out of the box plugin and a customisation approach to deal with the issue.
Overview
For many users having to enter a password to access a system is a pain. With most enterprise users having access to multiple systems it’s not only an extra set of key presses and mouse clicks that the user can do without but often there are lots of different passwords to remember (which in itself can lead to unfortunate security issues – e.g. writing passwords on pieces of paper to help the user remember!).
Of course many companies have become keen on systems that provide single sign on (SSO). There are a number of products deployed to support such schemes and Documentum provides support for some of them. One such product is CA Site Minder – formerly Netegrity SiteMinder and much of the EMC literature still refers to it as such.
SiteMinder actually consists of a number of components; the most relevant to our discussion are the user account database and the web authentication front-end. SiteMinder maintains a database of user accounts and authentication features and exposes an authentication API. Web-based SSO is achieved by a web-service that provides a username/password form, processes the form parameters and (on successful authentication) returns a SSO cookie to the calling application.
Documentum’s SiteMinder integration consists of 2 components. A WDK component that checks whether a SSO cookie has been set and a Content Server authentication plugin that will use the SiteMinder API to check the authentication of a user name/SSO cookie authentication pair.
How it works
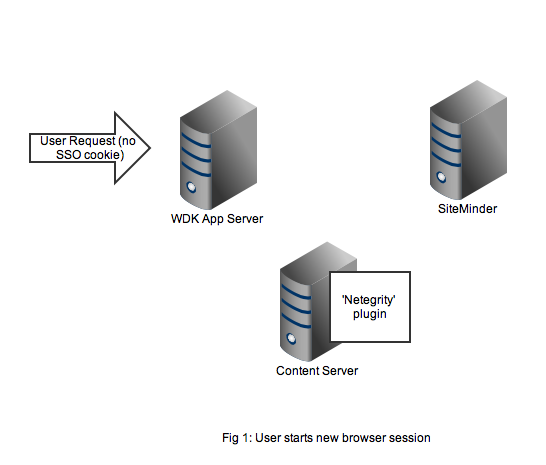
As usual it’s best to get an understanding by looking at the flow of requests and messages. Let’s take the case of a user opening a new browser session and navigating to a SSO-enabled WDK application (it could be webtop, web publisher or DCM). In Figure 1 we see a new HTTP request coming into the application server. At this point there is no SSO cookie and code in the WDK component can check this and redirect to a known (i.e. configured in the WDK application) SiteMinder service. I’ve also seen setups where the app server container itself (e.g. weblogic) has been configured to check for the SSO cookie and automatically redirect.
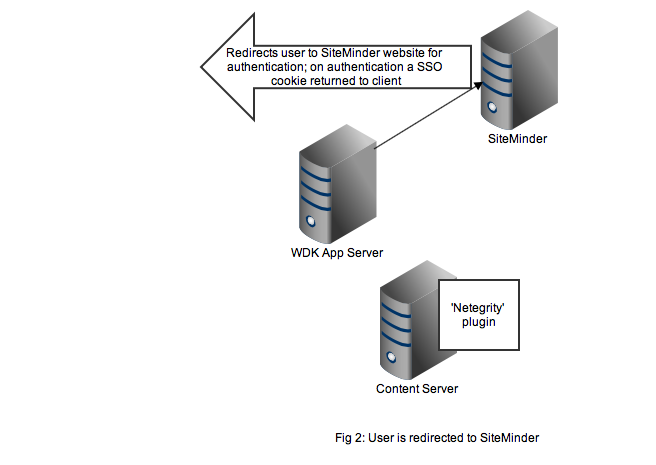
Redirection to the SiteMinder service will display an authentication form, typically a username and password but I guess SiteMinder also has extensions to accept other authentication credentials. As shown in Figure 2, on successful authentication the response is returned to the client browser along with the SSO cookie. Typically at this point the browser will redirect to back to the original WDK url. The key point is any subsequent requests to the WDK application will contain the SSO cookie.
Any user that wants to perform useful work in a WDK application will need an authenticated Documentum session. In non-SSO Documentum applications our user would have to authenticate to the Content Server via a WDK username/password form. In SSO Documentum applications, if we need to authenticate to a Content Server (and we have a SSO cookie) WDK silently passes the username and SSO cookie to the Content Server. Our SSO-enabled Content Server will do the following:
- Look up the username in it’s own list of dm_user accounts
- Look to see that the user_source attribute is indeed set to ‘dm_netegrity’
- Passes the username and SSO token (i.e. the cookie) to the dm_netegrity plugin to check authentication
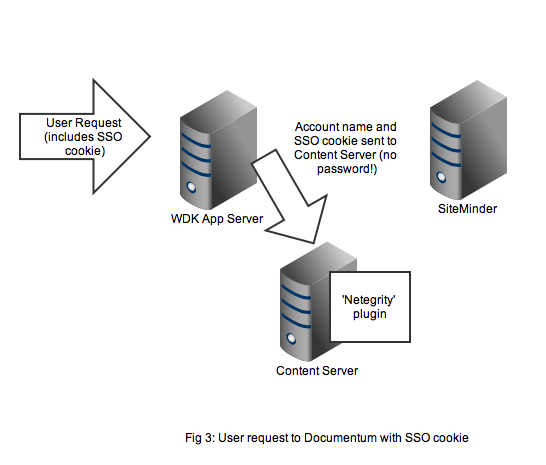
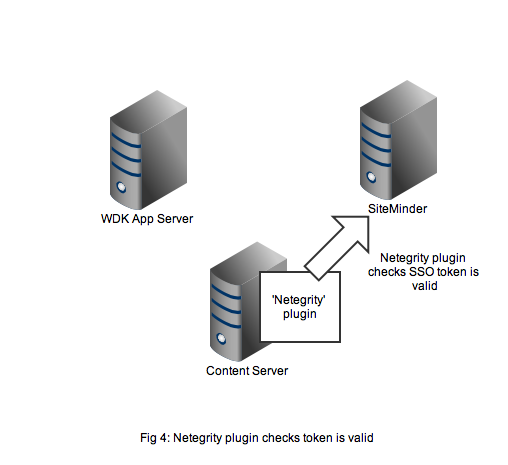
Figure 4 shows that the netegrity plugin will contact the SiteMinder service using the authentication API. The SiteMinder server confirms 2 things. First that the user account is indeed present in its database and secondly that the SSO token is valid and was issued for that user.
In Figure 5 we see that a successful authentication of the SSO token with SiteMinder means that the Netegrity plugin confirms authentication to the content server. A valid Documentum session will be created for the user and the user can continue to work. All without any Documentum user account and password form being displayed.
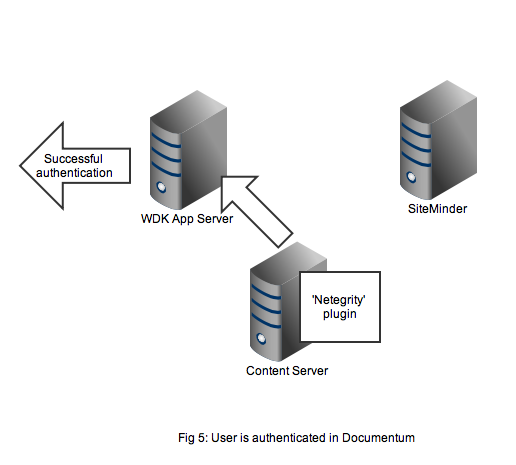
That concludes the overview of the out of the box working of the Documentum SiteMinder integration. The 2nd part of this article discusses a problem that manifests in compliance situations.
Taking the EMC Data Science associate certification
May 13, 2013 at 10:06 am | Posted in Big Data, Performance | 12 CommentsTags: Big Data, data science, emc, Greenplum, machine learning, Pivotal
In the last couple of weeks I’ve been studying for the EMC data science certification. There are a number of ways of studying for this certificate but I chose the virtual learning option,which comes as a DVD that installs on a Windows PC (yes Macs are no good!).
The course consists of six modules and is derived from the classroom-based delivery of the course. Each module is dedicated to a particular aspect of data science and big data with each following a similar pattern: a number of video lectures and followed by a set of lab exercises. There are also occasional short interviews with professional data scientists focusing on various topical areas. At the end of each module there is a question and answer multiple-choice to test your understanding of the subjects.
The video lectures are a recording of the course delivered to some EMC employees. This has some pros and cons. Occasionally we veer off from the lecture to a group discussion. Sometimes this is enlightening and provides a counterpoint to the formal material, however sometimes microphones are switched off or the conversation becomes confused and off-topic (just like real life!). Overall this worked pretty well and make if easier to watch.
The labs are more problematic. You get the same labs as delivered in the classroom course however you simply get to watch a camtasia studio recording of the lab with a voiceover by one of the presenters. Clearly the main benefits of labs is to enable people to experience the software hands-on, an essential part of learning practical skills. Most of the labs use either the open source R software or EMCs own Greenplum which is available as a community software download. There is nothing to stop you from downloading your own copies of these pieces of software and in fact that is what I did with R. However many of the labs assume there are certain sets of data available on the system; in some cases this is CSV files which are actually provided with the course. However relational tables used in Greenplum are not provided. It would have been nice if a dump of the relational tables had been provided on the DVD. A more ambitious idea would have been to provide some sort of online virtual machine in which subscribers to the course could run the labs.
Since the lab guide was provided I was able in many cases to follow the labs exactly, where the data was provided, or something close to it by generating my own data. I also used an existing Postgres database as a substitute for some of the Greenplum work. However I didn’t have time to get MADLib extensions working in Postgres (these come as part of out-of-the-box Greenplum). This is unfortunate as clearly one of the things that EMC/Pivotal/Greenplum would like is for more people to use MADLib. By the way, if you didn’t know, MADLib is a way of running advanced analytics in-database with the possibility of using Massively Parallel Processing to speed delivery of results.
The first couple of modules are of a high-level nature aimed more at Project Manager or Business Analyst type people. The presenter, David Dietrich, is clearly very comfortable with this material and appears to have had considerable experience at the business end of analytics projects. The material centres around a 6-step, iterative analytics methodology which seemed very sensible to me and would be a good framework for many analytics projects. It emphasises that much of the work will go into the early Discovery phases (i.e. the ‘What the hell are we actually doing?” phase) and particularly the Data Preparation (the unsexy bit of data projects). All in all this seemed both sensible and easy material.
Things start getting technical in Module 3 which provides background technicals on statistical theory and R, the open-source statistics software. The course assumes a certain level of statistical background and programming ability and if you don’t have that this is where you might start to struggle. As an experienced programmer I found R no problem at all and thoroughly enjoyed both the programming and the statistics.
The real meat of the course is Modules 4 and 5. Module 4 is a big beast as it dives into a number of machine learning algorithms: Kmeans clustering, Apriori decision rules, linear and logistic regression, Naive Bayes and Decision Trees. Throw in some introductory Text Analysis and you have a massive subject base to cover. This particular part of the course is exceptionally well-written and pretty well presented. I’m not saying it’s perfect but it is hard to over-state how difficult it is to cover all this material effectively in a relatively short-space of time. Each of these algorithms is presented with use-cases, some theoretical background and insight, pros and cons, and a lab.
It should be acknowledged that analytics and big data projects require a considerable range of skills and this course provides a broad-brush overview of some of the more common techniques. Clearly you wouldn’t expect participation on this course to make you an expert Data Scientist any more than you would employ someone to program in Java or C just based on courses and exams taken. I certainly wouldn’t let someone loose to administer a production Documentum system without being very sure they had the tough experience to back up the certificates. Somewhere in the introduction to this course they make clear that the aim is to enable the you to become an effective participant in a big data analytics project; not necessarily as a data scientist but as someone who needs to understand both the process and the technicals. As far as this is the aim I think it is well met in Module 4.
Module 5 is an introduction to big data processing, in particular Hadoop and MADLib. I just want to make 1 point here. This is very much an overview and it is clear that the stance taken by the course is that a Data Scientist would be very concerned with technical details about which analytics methods to use and evaluate (the subject of module 4), however the processing side is just something that they need to be aware of. I suspect in real-life that this dichotomy is nowhere near as clear-cut.
Finally Module 6 is back to the high-level stuff of modules 1 and 2. Some useful stuff about how to write reports for project sponsors and other non-Data Scientists and dos and don’ts of diagrams and visualisations. If this all seems a bit obvious it’s amazing how often this is done badly. As the presenter points out it’s no good spending tons of time and effort producing great analytics if you aren’t able to effectively convince your stakeholders of your results and recommendations. This is so true. The big takeaways: don’t use 3D charts, and pie charts are usually a waste of ink (or screen real estate).
If I have one major complaint about the content it is that Feature Selection is not covered in any depth. It’s certainly there in places in module 4 but given that coming up with the right features to model on can have a huge impact on the predictive power of your model there is a case for specific focus.
So overall I think this was a worthwhile course as long as you don’t have unrealistic expectations of what you will achieve. Furthermore if you want to get full value from the labs you are going to have to invest some effort in installing software (R and Greenplum/Postgres) and ‘munging’ data sets to use.
Oh, by the way, I passed the exam!
Create a free website or blog at WordPress.com.
Entries and comments feeds.

You must be logged in to post a comment.